Independent benchmarks rank Rust AutoAgents ahead of Python agent frameworks
An independent Feb 18, 2026 benchmark ranked Rust AutoAgents top with score 98.03, reporting a 4 ms cold start, 4.97 rps throughput, 5,714 ms avg latency and 1,046 MB peak memory.
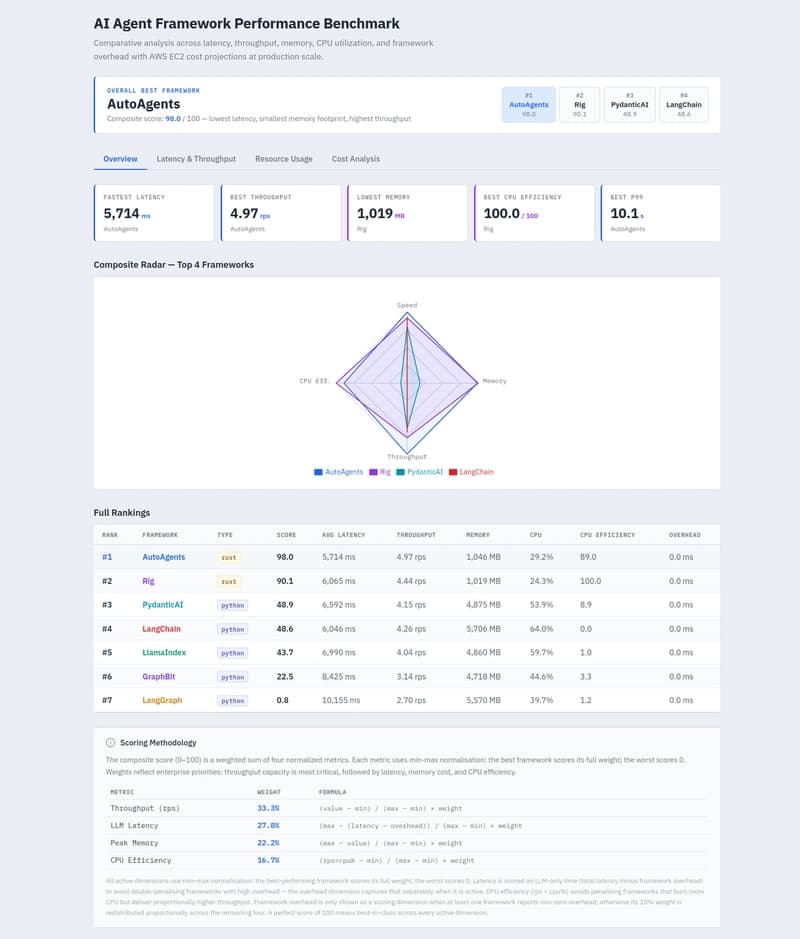
An independent benchmark published Feb 18, 2026 put the Rust-based AutoAgents framework ahead of popular Python agent frameworks on multiple production-oriented metrics. The Dev.to-style results table lists AutoAgents with a composite score of 98.03, average latency 5,714 ms, P95 9,652 ms, throughput 4.97 rps, peak memory 1,046 MB, CPU 29.2%, and a 4 ms cold start. At the bottom of that same table, LangGraph scores 0.85 with 10,155 ms avg latency, 16,891 ms P95, 2.70 rps throughput, 5,570 MB peak memory, 39.7% CPU, and a 63 ms cold start.
The benchmark author highlighted why those numbers matter in production: “Python frameworks carry baseline weight you pay even when idle: interpreter, dependency tree, dynamic dispatch, GC. Rust's ownership model means memory is freed immediately when objects go out of scope, no GC heap to keep around.” The Dev.to dataset shows Rust alternatives clustered at roughly 1,000 MB peak memory (AutoAgents 1,046 MB, Rig 1,019 MB) while Python frameworks in the table show multi-gigabyte peaks (LangChain 5,706 MB, PydanticAI 4,875 MB, LlamaIndex 4,860 MB). CPU usage differences were also pronounced: Rig 24.3% (the most efficient), AutoAgents 29.2%, and LangChain 64.0%.
Latency patterns in the Dev.to writeup stressed the role of model network time: “Latency differences are more nuanced. The LLM network round-trip dominates, which is why all frameworks cluster between 5,700 and 7,000 ms. The outliers (GraphBit at 8,425 ms, LangGraph at 10,155 ms) reflect additional framework orchestration overhead.” Using the table’s numbers, the author concluded AutoAgents “beats the average Python framework by 25% on latency” and delivers “36% more throughput under the same concurrency” versus the Python average (4.97 rps vs 3.66 rps).
A separate vendor benchmark from AgentSDK reported even larger Rust advantages on a different testbed: AgentSDK measured a 2.3 ms cold start, 12 MB idle memory, and 8,400 req/s throughput on an M3 Max MacBook Pro with 64GB RAM using Claude Sonnet 4. AgentSDK contrasted those figures with LlamaIndex (89 ms cold start, 164 MB idle memory, 920 req/s) and LangChain (108 ms, 218 MB, 680 req/s) and claimed multipliers such as “47x improvement over LangChain” on cold start and “12x higher throughput.” The two sources use different metrics and scales - Dev.to reports rps in single digits under a production-oriented workload while AgentSDK reports thousands of req/s on a specified hardware/model setup - so the absolute numbers are not directly comparable without full methodology alignment.

Community discussion amplified the practical tradeoffs. On LinkedIn, Serdar Yegulalp wrote “The rust chat response times were almost 10-25% faster than python (even with running a litellm proxy on docker)” while warning that ecosystem gaps remain: “Any rust implementation similar to litellm out there supports max 10 providers. Compare that to 100+ in litellm. I had to run litellm proxy on a docker container for AutoAgents.” AutoAgents creator Ashish Shah replied asking for feedback on missing integrations.
Researchers push this debate beyond raw speed. Scouts Yutori’s paper “Towards a Science of AI Agent Reliability” proposes a performance profile across consistency, robustness, predictability and safety and argues benchmarks should track degradation and predict failures. The Feb 18 independent results and AgentSDK’s M3 Max numbers together make a clear technical claim: Rust-native agents consistently show large advantages on cold start, memory and CPU efficiency, but differing testbeds and ecosystem maturity mean teams should reproduce these tests against their own LLMs, workloads and integration needs before committing to one stack.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?


