OpenAI strikes multibillion-dollar deal with Cerebras for low-latency inference
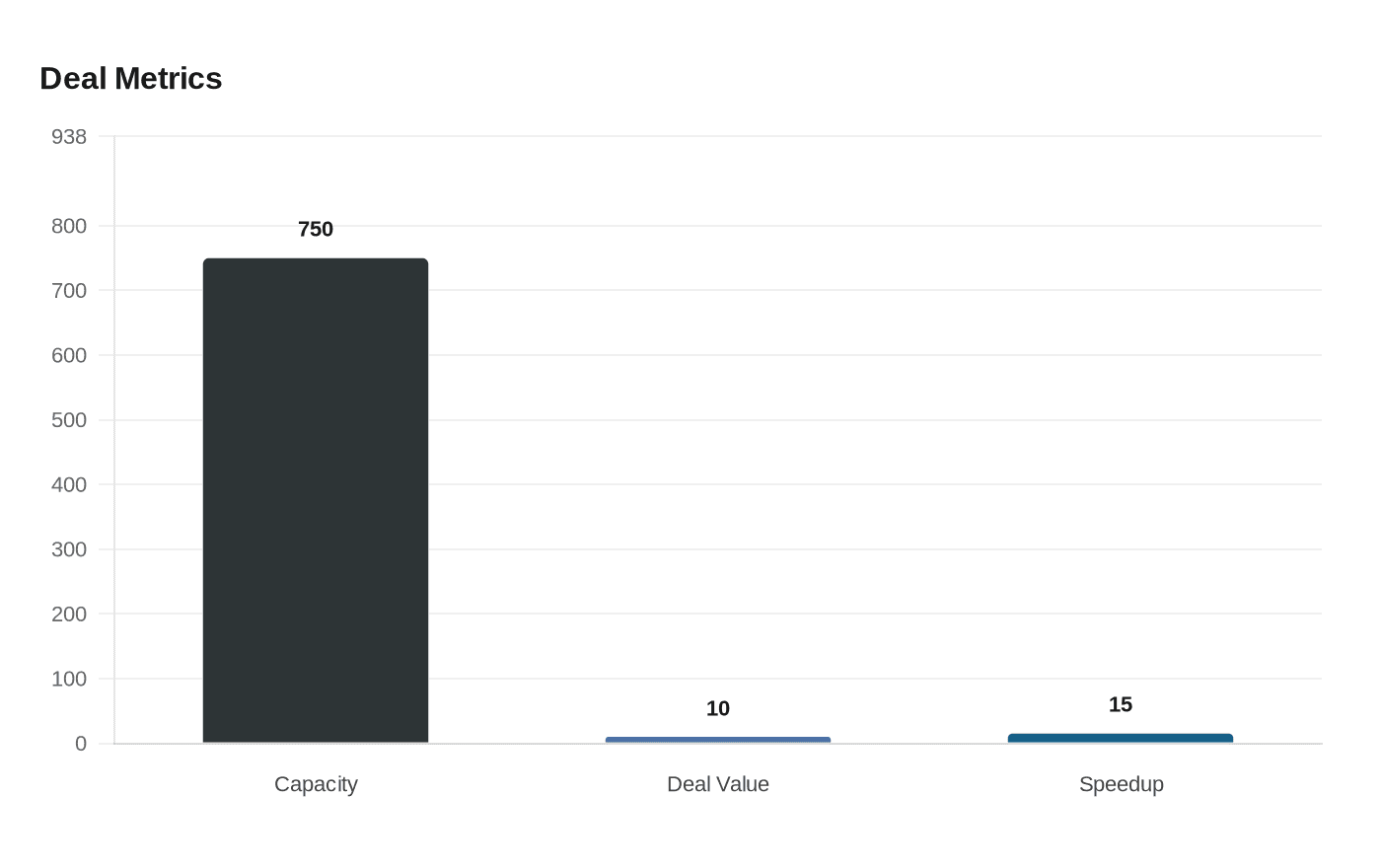
OpenAI agreed to buy up to 750 megawatts of Cerebras wafer-scale inference compute through 2028, a deal reported as worth more than $10 billion and aimed at speeding real-time AI.
%2Fsocialsamosa%2Fmedia%2Fmedia_files%2F2026%2F01%2F15%2F21-2026-01-15-11-45-23.jpg&w=1920&q=75)
OpenAI has reached a multi-year commercial agreement to integrate Cerebras Systems’ wafer-scale AI hardware into its compute mix, securing up to 750 megawatts of low-latency inference capacity to be delivered in tranches through 2028. The arrangement has been widely reported as exceeding $10 billion in value and is intended to accelerate response times for the company’s most advanced models in interactive applications.
The capacity purchase would provide a distinct class of hardware optimized for short request-response loops. Cerebras’ wafer-scale "big-chip" processors, deployed in CS-3 class systems and as a cloud service, consolidate large amounts of compute, memory and bandwidth on a single silicon package to reduce the interconnect bottlenecks of conventional GPU clusters. Industry commentary around the deal has highlighted potential inference speedups of up to 15 times for certain workloads, positioning the hardware as an "ultra-low-latency" option for tasks that demand immediate output.
OpenAI framed the acquisition as part of a broader compute-portfolio strategy, matching specific system architectures to particular workloads. "OpenAI’s compute strategy is to build a resilient portfolio that matches the right systems to the right workloads. Cerebras adds a dedicated low‑latency inference solution to our platform. That means faster responses, more natural interactions, and a stronger foundation to scale real-time AI to many more people," said Sachin Katti of OpenAI.

Cerebras welcomed the tie-up as a high-profile customer win that could accelerate commercial traction. "We are delighted to partner with OpenAI, bringing the world’s leading AI models to the world’s fastest AI processor," said Andrew Feldman, co-founder and CEO of Cerebras.
The deal carries immediate market implications. For OpenAI, adding wafer-scale processors supplements its existing mix of Nvidia and AMD GPUs and Google TPUs, and complements its advisory and development work on other chip initiatives. OpenAI has previously signaled ambitions to scale to 30 gigawatts of compute capacity, a target that would equal 30,000 megawatts; the Cerebras tranche of up to 750 megawatts would represent roughly 2.5 percent of that long-range goal. For Cerebras, the agreement could diversify revenue and reduce customer concentration, strengthening the company’s position ahead of potential capital markets moves that it had been preparing.
Energy and infrastructure considerations are central to the economics of the deal. A commitment of hundreds of megawatts of dedicated compute capacity entails substantial power procurement, real estate and cooling buildout, and long-term power purchase agreements. Those operational costs will influence unit economics for inference services and could affect pricing dynamics for latency-sensitive AI applications such as real-time agents, voice assistants and coding copilots.
Policy and industrial strategy questions follow from rapid growth in hyperscale compute demand. Large, concentrated investments in specialized processors raise issues around grid resilience, regional permitting, and supply-chain diversification. They may also accelerate competition among chip vendors to deliver differentiated hardware for inference rather than raw training throughput.
Specific delivery schedules, the split between on-premises deployments and Cerebras cloud-hosted systems, and contractual payment terms were not disclosed. OpenAI said the Cerebras capacity will be integrated in phases and expanded across workloads over time as part of its effort to scale real-time AI services.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?

