TokioConf talk shows async Rust assumptions break at 45M requests per second
45M req/s is where Tokio intuition breaks: one Rust team saw 30% drops and 450ms p99, then had to relearn profiling, cancellation, and observability.
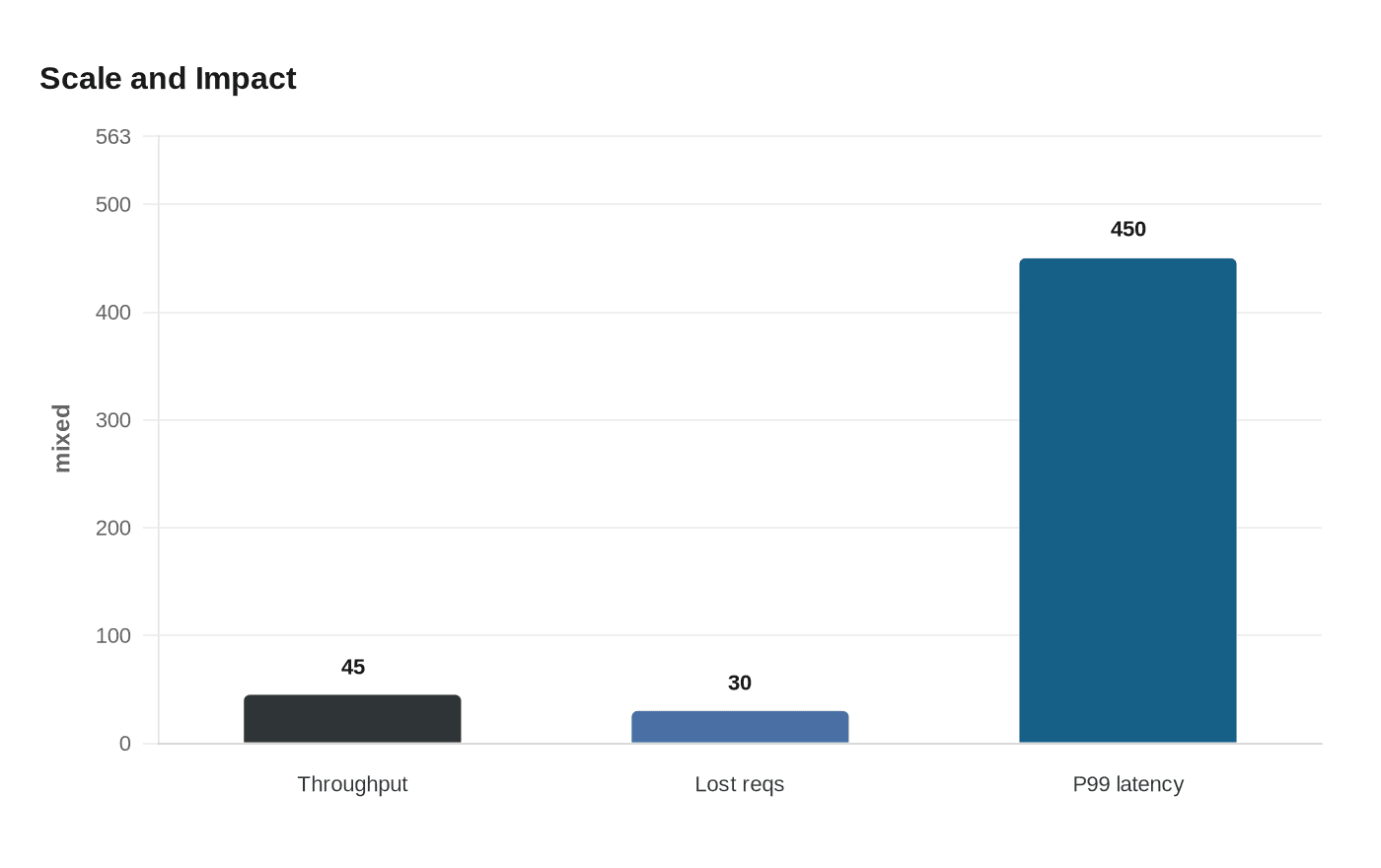
45M requests per second is where async Rust stops rewarding guesswork. In Wojciech Kargul’s TokioConf talk, a service that had once felt healthy at 10M req/s suddenly found itself staring at 45M req/s, 30% of requests disappearing, and P99 latency climbing to 450ms. The team’s answer was not a quick tuning pass. It was a 72-hour sprint to rebuild their understanding of how Tokio systems actually behave under pressure.
When the numbers outgrow your assumptions
The talk title says the quiet part out loud: “Zero-Copy Chaos. When everything you knew about tokio performance stopped working.” That is the right framing for this kind of failure, because the problem is rarely one dramatic bug. It is usually a stack of good-enough assumptions that held at 10M req/s and then fell apart when traffic quadrupled.
That shift matters because Tokio is already designed for serious throughput. Tokio describes itself as a multi-threaded, work-stealing scheduler for reliable async applications, and its own positioning says applications can process hundreds of thousands of requests per second with minimal overhead. At that point, you are not fighting the runtime’s baseline capabilities anymore. You are fighting the places where your own mental model of the system is too simple.
What breaks as Rust systems scale
The most useful part of this story is not that the service got fast enough to be impressive. It is that the familiar Rust optimization instincts became unreliable once the workload hit 45M req/s. Zero-copy, buffer reuse, and abstraction shaving are all valid tools, but they do not automatically win when the real bottleneck sits somewhere else in the pipeline.
That is why the talk’s lesson lands so hard for people building production async systems: profile first, then decide what to cut. At scale, intuition often points at the wrong layer, especially when the executor, scheduling behavior, or observability overhead is quietly dominating the request path. The 72-hour rebuild in Kargul’s profile is a reminder that a system can look elegant in code and still behave badly in production.
Why TokioConf exists for this exact pain
TokioConf 2026 was built around these kinds of failures. It was the inaugural dedicated conference for developers building asynchronous network applications in Rust, scheduled for April 20-22, 2026 in Portland, Oregon, and organizers said it was expected to gather 300 developers. The format was a single-track event, which fits the subject: this is not a conference for broad slogans, it is a place to dig into the parts of async Rust that break first.
The program was set to include talks, panels, lightning talks, and a workshop on async Rust and the Tokio runtime. Tokio’s broader conference messaging also emphasized network programming, instrumentation, cancellation, and diagnosing issues like tasks blocking the executor. That combination tells you exactly where the community thinks the sharp edges are: not just raw throughput, but how to understand the system when the easy metrics stop telling the truth.
Observability is part of the performance stack now
The appearance of dial9 in March 2026 pushes the same lesson further. Tokio’s blog said runtime-scale issues often require correlating Tokio runtime events, application spans and logs, and Linux kernel events rather than relying only on aggregate metrics. That is a very different debugging posture from the old “CPU looks fine, latency looks bad, shrug” routine.
For production Rust, that means instrumentation is not a luxury layer on top of the real work. It is part of the work. If tasks are blocking the executor, if cancellation behavior is messy, or if the request path is being distorted by events below your app code, aggregate dashboards can flatter you right up until the system starts dropping traffic.
The surprising takeaways that matter in practice
A few things stand out from this talk and the conference around it:
- 10M req/s is not “done.” It can be the point where your assumptions are just getting comfortable.
- Zero-copy is a tactic, not a moral stance. If the hot path is elsewhere, it can distract you from the real bottleneck.
- P99 is where the story gets honest. A system dropping 30% of requests and hitting 450ms at the tail is telling you that the happy path is no longer the important path.
- Profiling has to happen before the theory hardens. Once the team spent 72 hours rebuilding their model, they were no longer debugging code. They were debugging assumptions.
- Runtime events matter as much as app metrics when Tokio systems get large enough to blur the line between code, scheduler, and kernel behavior.
TokioConf’s real value is that it turns those lessons into a shared language for people building serious networked Rust systems. When a service jumps from 10M req/s to 45M req/s, the runtime is not just running faster. It is revealing every place where the old story about performance was too neat to survive contact with production.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?