Google's TurboQuant AI Algorithm Shrinks Memory 6x, Sparks Pied Piper Comparisons
Google's TurboQuant shrinks AI memory by 6x with zero accuracy loss, and the internet can't stop calling it Silicon Valley's fictional Pied Piper.

Google Research published TurboQuant this week, a training-free compression algorithm that quantizes LLM key-value caches down to 3 bits without any loss in model accuracy, and the internet's first instinct was to reach for a TV reference. Comparisons to Pied Piper, the fictional compression startup from HBO's "Silicon Valley," spread quickly across AI forums and social media, a reaction that underscored just how striking the claims are.
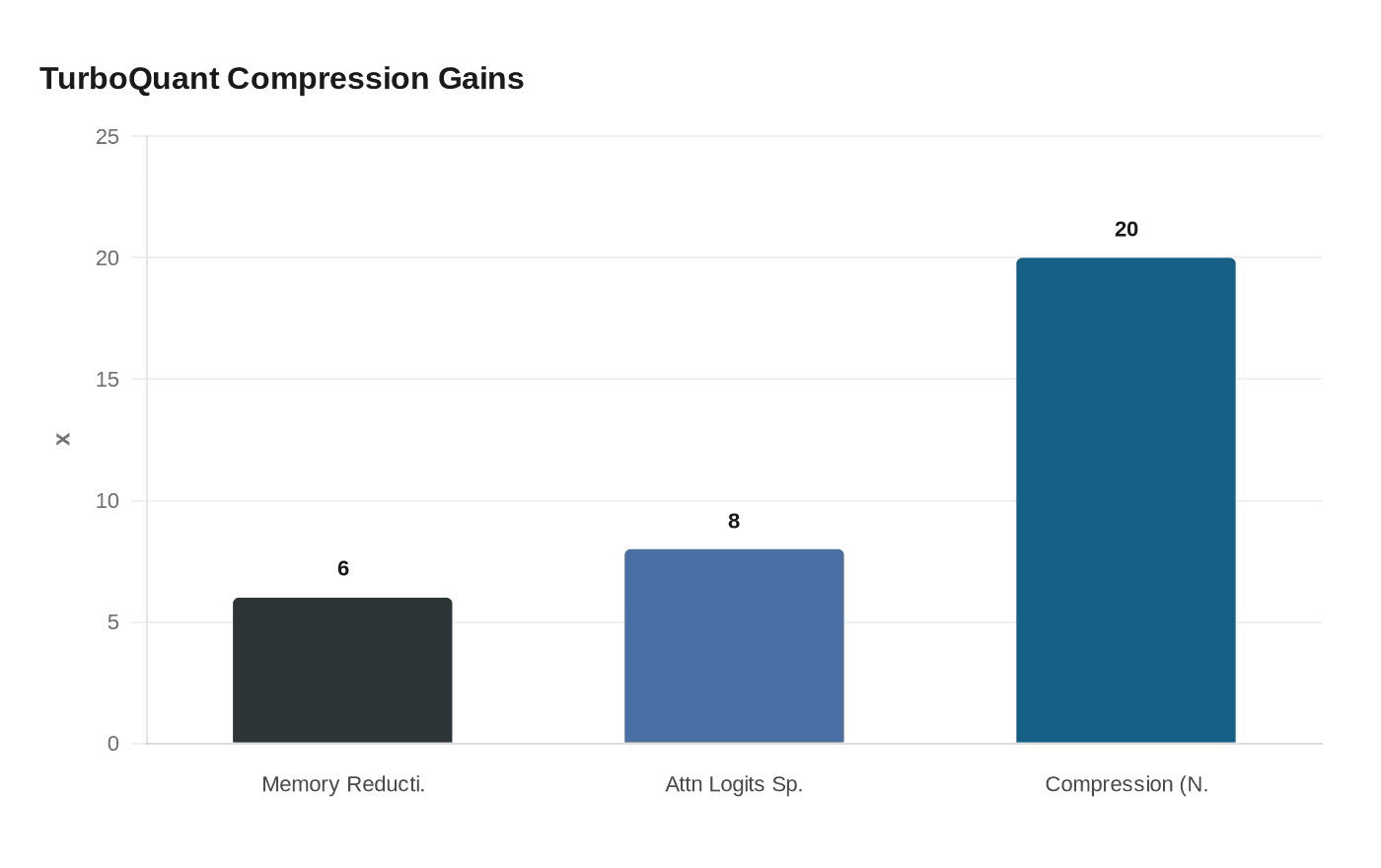
The algorithm compresses the KV cache of large language models to 3 bits, significantly reducing memory usage by at least 6x without compromising accuracy. In benchmarks on Nvidia H100 GPUs, 4-bit TurboQuant delivered up to an eight-times performance increase in computing attention logits compared to unquantized 32-bit keys.
The KV cache is the architectural pressure point TurboQuant targets. KV caches store previously computed attention data so that LLMs don't have to recompute it at each token generation step. These caches are becoming major memory bottlenecks as context windows grow larger, and while traditional vector quantization methods can reduce the size of these caches, they introduce a small memory overhead of a few extra bits per value from the quantization constants that must be stored alongside the compressed data.
TurboQuant's first component, PolarQuant (to appear at AISTATS 2026), converts vectors from Cartesian to polar coordinates, which eliminates the need to store per-block normalization constants. Traditional quantization methods waste 1 to 2 bits per number on these constants, which partially defeats the purpose of quantizing in the first place. PolarQuant sidesteps this by mapping data onto a fixed circular grid where the boundaries are already known. The second piece, Quantized Johnson-Lindenstrauss (QJL), is a 1-bit error correction step. After PolarQuant does the heavy compression, QJL takes the leftover error and reduces each residual vector to a single sign bit.
Google noted that TurboQuant requires no training or fine-tuning and incurs negligible runtime overhead, making it suitable for deployment in production inference and large-scale vector search systems. Testing on open-source LLMs like Gemma and Mistral across benchmarks including LongBench and Needle In A Haystack showed strong performance and minimized key-value memory footprint.
The paper, co-authored by research scientist Amir Zandieh and VP Vahab Mirrokni, will be presented at ICLR 2026 next month. TurboQuant will be formally presented at ICLR 2026 in late April, when the main conference runs April 23-25. Its companion paper, PolarQuant, will be presented at AISTATS 2026 around the same time.
Google's decision to publish openly rather than keep the techniques proprietary is drawing as much attention as the compression numbers themselves. Within 24 hours of the release, community members began porting the algorithm to popular local AI libraries like MLX for Apple Silicon and llama.cpp. The paper provides theory and pseudocode, but there is no official open-source implementation yet, and community integration work has started.
TurboQuant has strong theory and good benchmarks but no deployment story yet. What is missing from the comparison is any head-to-head with Nvidia's KVTC, which was also accepted at ICLR 2026 and claims up to 20x compression. For now, the research community is treating TurboQuant as a significant milestone in the shift toward on-device inference, even if the path from paper to production remains uncharted. As AI progress moves deeper into 2026, TurboQuant suggests the next era will be defined as much by mathematical elegance as by brute force.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?


