Leaked Anthropic Drafts Reveal Unannounced Claude Mythos Model With Cybersecurity Risks
A CMS misconfiguration exposed nearly 3,000 Anthropic internal files, unveiling an unannounced Claude Mythos model that the company's own drafts flagged for cybersecurity risks.
A misconfigured content management system left nearly 3,000 unpublished internal documents from Anthropic publicly accessible without authentication, exposing draft materials describing an unannounced AI model the company had been developing under the name Claude Mythos — a model Anthropic's own internal teams flagged as capable of finding and exploiting software vulnerabilities.
Researchers at LayerX Security and academic collaborators discovered the exposed cache and alerted outlets including Fortune, prompting Anthropic to restrict access. The company confirmed the incident, described it as a CMS misconfiguration unrelated to its production systems including Claude itself, and characterized the leaked materials as early drafts.
The documents paint a portrait of a model that Anthropic's own drafters described as "the most capable we've built to date," positioned internally under the codename Capybara at a tier above the company's existing Opus line. The draft materials credited Mythos with significant advances in reasoning, coding and cybersecurity-related tasks relative to Opus, but it was the internal risk disclosures that drew the sharpest attention.
Some of the leaked materials included explicit warnings about Mythos's potential to autonomously locate and exploit software weaknesses, a capability Anthropic itself characterized as meriting special caution. Those warnings, drafted by the company's own teams, became operationally significant the moment they left the controlled environment of Anthropic's internal systems.
Security researchers noted that even draft-stage disclosures about a model's offensive capabilities carry real intelligence value for adversaries mapping their own attack surfaces. The market reacted accordingly: cybersecurity equity prices softened as investors processed the implications of a frontier model with autonomous vulnerability-discovery capabilities entering the public discussion prematurely, before any formal announcement or guardrail documentation had been released.
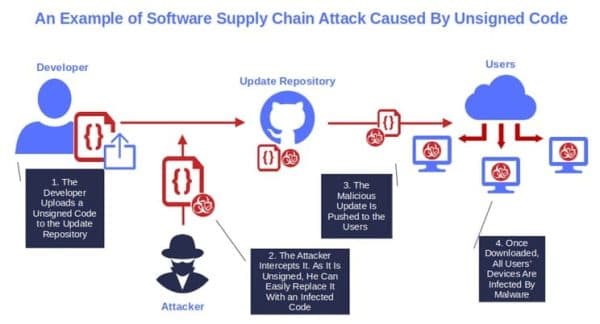
Anthropic confirmed it was testing a model that represented a "step change" in capability but stressed the draft nature of everything exposed. The root cause was a human or configuration error in an external CMS rather than any intrusion into its development infrastructure. The misconfiguration left items accessible simply because they had not been marked private, enabling automated discovery and bulk download by independent researchers without triggering any authentication challenge.
The incident arrives at a moment when frontier AI developers face simultaneous pressure to move quickly and to demonstrate that accelerating capability does not outrun operational security. For enterprise buyers and regulators, the episode sharpens a procurement question that has been building across the industry: what risk controls govern models that carry internally documented offensive security capabilities, and who decides when those capabilities are disclosed? Anthropic now faces audits of its publishing infrastructure, forensic review of what was accessed, and the harder task of clarifying to customers and policymakers exactly what guardrails govern a model its own teams described as uniquely dangerous.
Sources:
Know something we missed? Have a correction or additional information?
Submit a Tip