Search teams race to measure AI citations across six surfaces
Rank tracking is not enough when AI citations are scattered across six surfaces. Agencies now need one system for overlap, inclusion, and proof of value.

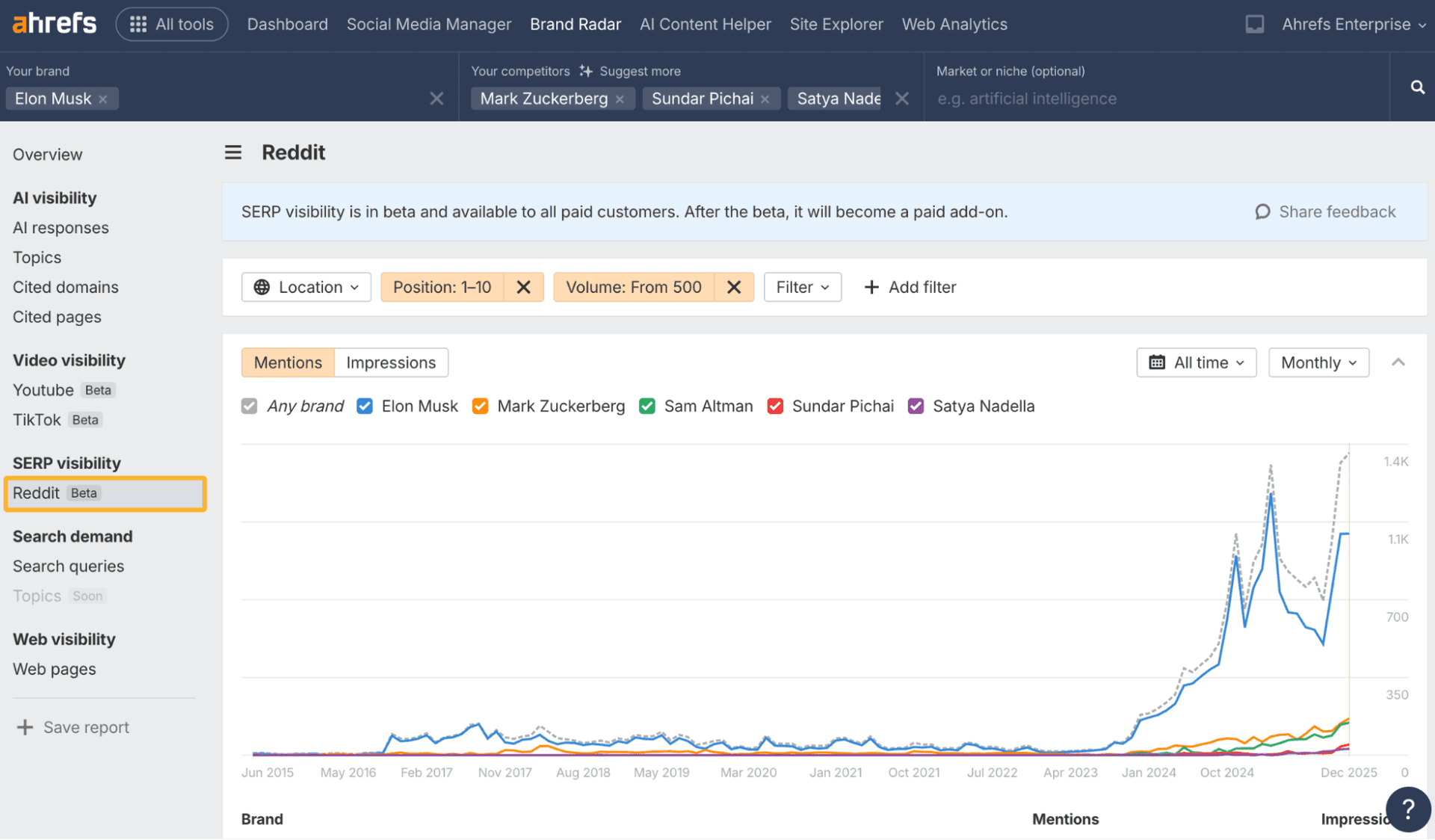
Across ChatGPT, Claude, Perplexity, AI Overviews, AI Mode, and other engines, the same page can appear in one AI answer and vanish in another. Search teams are moving from rank reports to citation maps because visibility now depends on where a brand is cited, how often it reappears, and whether that attention turns into pipeline. The agencies that can explain that chain in one client-ready report are best positioned to protect budgets and win strategic work.
Why the old rank report breaks down
Search Engine Journal’s June 23 session centers on a problem that has become operational rather than theoretical: teams can still see rankings, but they struggle to measure citations, inclusion, and influence across multiple AI surfaces. The issue is not confined to one product release or one platform. The supporting data sits across six to twelve tools that do not integrate cleanly, leaving agencies stitching together a story from fragmented dashboards.
That fragmentation changes the unit of work. A monthly rank report once told a simple story about position, traffic, and change. Now clients want to know where content appeared, which engines cited it, what changed over time, and how that visibility translated into business value. In that environment, agencies that keep AI search in a separate silo lose the reporting thread that budget holders actually need.
What agencies should measure instead of rank alone
The shift is not just toward more data, it is toward different data. HubSpot treats AI citation tracking as a visibility metric because AI-powered search experiences are shaping how people discover information, evaluate vendors, and build shortlists before they click through. Lumar argues that SEO teams need to optimize for representation, inclusion, and influence across AI-generated answers, not rankings alone.
That means reporting has to expand beyond position tracking. A useful agency dashboard now needs to show:
- citation volume by surface, including ChatGPT, Claude, Perplexity, AI Overviews, and AI Mode
- source overlap, so teams can see when different engines favor the same or different pages
- brand-name overlap, which shows whether the company itself is present even when the linked source changes
- update velocity, meaning how quickly fixes were shipped after a citation gap appeared
- post-publication verification, so teams can confirm whether a change held after it went live
What the current data says about six surfaces
The strongest reason to build a citation workflow is that source selection varies sharply by engine. BrightEdge looked at five AI search surfaces, ChatGPT, Google AI Overviews, Google AI Mode, Google Gemini, and Perplexity, and found wide variation in cited sources. Source overlap ranged from 16 percent at the low end to 59 percent at the high end, while brand-name overlap ranged from 36 percent to 59 percent across those surfaces.
A separate xfunnel.ai analysis covered 40,000 responses and 250,000 citations. In that sample, Perplexity averaged 6.61 citations per response, Google Gemini averaged 6.1, and ChatGPT averaged 2.62. Earned third-party content accounted for the largest share of citations.
How a working citation system gets built
Sam Garg, founder and chief executive of Writesonic, outlined the operating model in Search Engine Journal’s June 23 webinar. Garg’s workflow uses AI agents to identify citation gaps, prioritize fixes, draft updates for review, and verify whether the changes held after publication.
Garg’s framework breaks a working marketing agent into four layers: identity, knowledge, skills, and loops. In practice, that means defining what the agent is supposed to do, what information it can use, what actions it can take, and how it checks its own work. The citation-outreach system goes a step further, surfacing opportunities and drafting outreach by 7 AM, with open-source components available for teams that want to assemble their own version.
For agencies, the labor-heavy parts of the workflow are the parts to standardize:
1. detect where a page is missing from cited answers on specific surfaces
2. prioritize fixes by business value, not by raw traffic alone
3. draft content updates or outreach for editorial review
4. verify whether the revised page is actually being cited afterward
How reporting changes when AI citations matter
The client report has to change shape. Instead of a single ranking chart, agencies need a visibility narrative that links surface coverage, source mix, and business consequences. A page that ranks well in traditional search but is ignored in AI Overviews may still need work if the client’s buyers are moving through AI-generated shortlists before they ever reach the website.
HubSpot frames AI citation tracking as a way to measure brand visibility and authority in AI-powered search results, while Lumar pushes teams toward representation, inclusion, and influence.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?