Rust article shows how to keep SIMD fast without unsafe clutter
Rust 1.87 cuts the unsafe tax on SIMD. If you can fence off feature detection, the hot loop can stay clean, fast, and auditable.
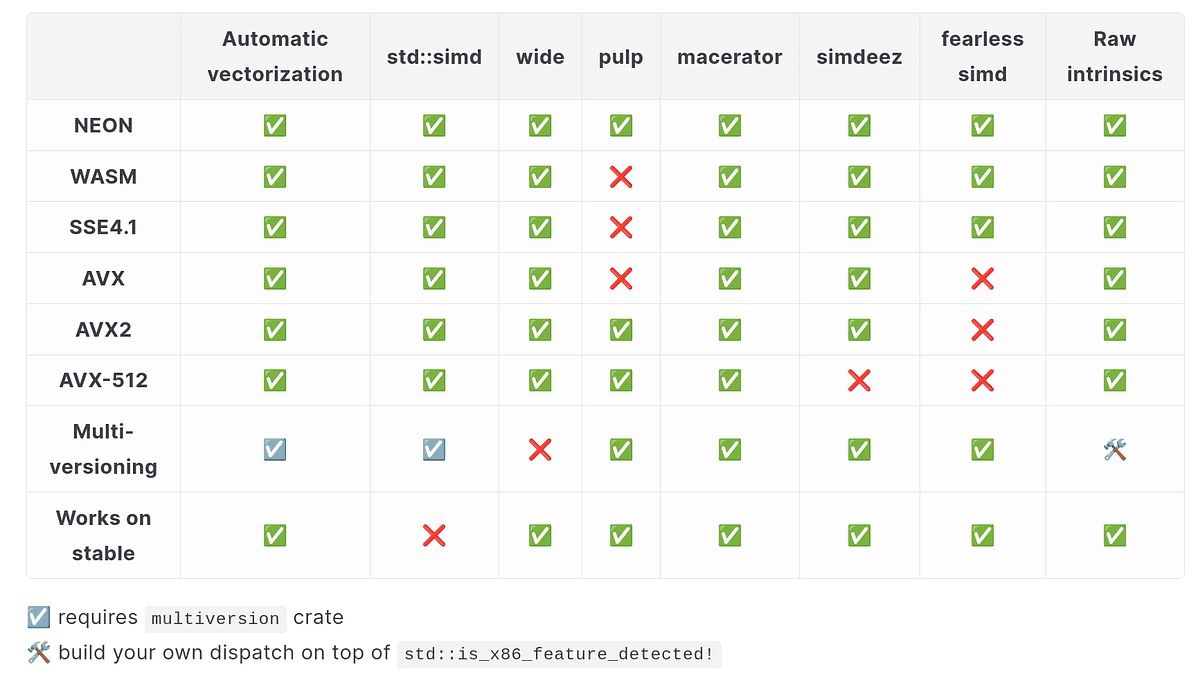
a + b` is still the ideal SIMD interface: ordinary-looking code with the compiler or library choosing the right instruction sequence underneath. Sergei Davidoff, who writes as Shnatsel, zeroes in on the problem every Rust performance nerd eventually hits: SIMD is only worth it if you can keep the codebase from turning into an unsafe landfill. The hard part is making that feel native across x86, AArch64, WebAssembly, 32-bit ARM, and the machines that have no SIMD at all.
Why SIMD used to get ugly fast
The old shape of SIMD in Rust was a compromise stack: feature probes, architecture-specific wrappers, slice loading code that massaged data into the layout intrinsics expected, and unsafe calls scattered at every call site. That is fine when you are hand-tuning one narrow kernel, but it gets brittle when the same code has to run on AVX2, SSE, AVX-512, NEON, WebAssembly, and plain scalar fallback paths. Each extra layer of branching also makes review harder, because now you are auditing both the math and the machine model.
SIMD is an architecture problem, not just a performance trick. If the abstraction leaks, you stop thinking about the work your code does and start thinking about which CPUs can even enter the function. In real systems code, that is where optimization gets expensive: the hot loop is no longer the only thing you are maintaining.
Rust 1.87 changed the safety boundary
The big shift came with Rust 1.87.0, released on May 15, 2025, during the RustWeek celebration in Utrecht, Netherlands, on the 10-year anniversary of Rust 1.0. Most `std::arch` intrinsics that were unsafe only because they required target features can now be called in safe code when those features are enabled.
Before that change, a function could be logically safe once the CPU feature gate was satisfied, but the compiler still forced you to mark the intrinsic call unsafe. Rust 1.87 tightened that boundary so the unsafe part can stay where the feature decision happens, not where the arithmetic runs. Rust 1.87 also arrived on Rust’s regular six-week cadence.
The AVX2 pattern is the useful one
The useful AVX2 pattern is to do the runtime feature probe once, keep that part at the unsafe boundary, and put the actual hot loop inside a `#[target_feature(enable = "avx2")]` function. The unsafe decision becomes, "Can I call this optimized path on this CPU?" while the body itself stays readable and testable.
You still need to detect the machine you are actually running on, but you no longer need every intrinsic call to wear an unsafe marker like a warning label. For a library author, that means one audited dispatch layer and a much calmer implementation below it. For an application developer, the fast path can look like normal Rust.
Portable SIMD has been the target for years
The Portable SIMD Project Group was announced on September 29, 2020, with the explicit goal of making a portable SIMD API available to stable Rust users. The goal was a portable SIMD API for stable Rust users, not more unsafe wrappers.
In its April 2022 aspirations, the Rust Library Team put Portable SIMD benchmarking alongside reducing and improving unsafe code. Rust is not treating safety and performance as tradeoffs that cancel each other out. It is pushing the unsafe boundary inward and giving the public API a shape that ordinary Rust can live with.
When safe SIMD is the right optimization path
Safe SIMD is worth the trouble when the same kernel runs often enough to justify a dispatch layer and the code can be isolated behind a narrow API. Think tight numeric loops, packet processing, image kernels, compression primitives, and any workload where the win comes from doing the same operation over a lot of elements. That is where a `#[target_feature]` function plus runtime selection pays for itself.
It is also the right move when your team needs to review and maintain the code after the original optimization push. One audited unsafe boundary is easier to reason about than a hundred small ones. If you can express the operation as a simple high-level interface and keep the feature-sensitive bits in a single module, Rust 1.87 makes that architecture feel much less awkward.
When the abstraction still costs too much
The gain is not free. If the hot path is tiny, called rarely, or buried under cache misses and allocations, the work to build a SIMD dispatch layer can be more expensive than the speedup. The same is true when you need to support a sprawling matrix of instruction sets and fallback behaviors but only get a marginal boost on the common case. At that point, you are shipping a SIMD dispatch layer as well as the code it is meant to accelerate.
That is the real judgment call. Rust has made the safe path much better, but it has not erased the need to decide whether vectorization is the bottleneck. If the answer is yes, Rust 1.87 gives you a cleaner way to wire it up. If the answer is maybe, the most honest optimization may still be to leave the scalar code alone.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?


