AI search visibility starts with being shortlisted, not cited
AI visibility work fails when agencies chase citations before the brand is shortlist-worthy. The real fix starts with category clarity, entity strength, and trust.
The mistake agencies keep making
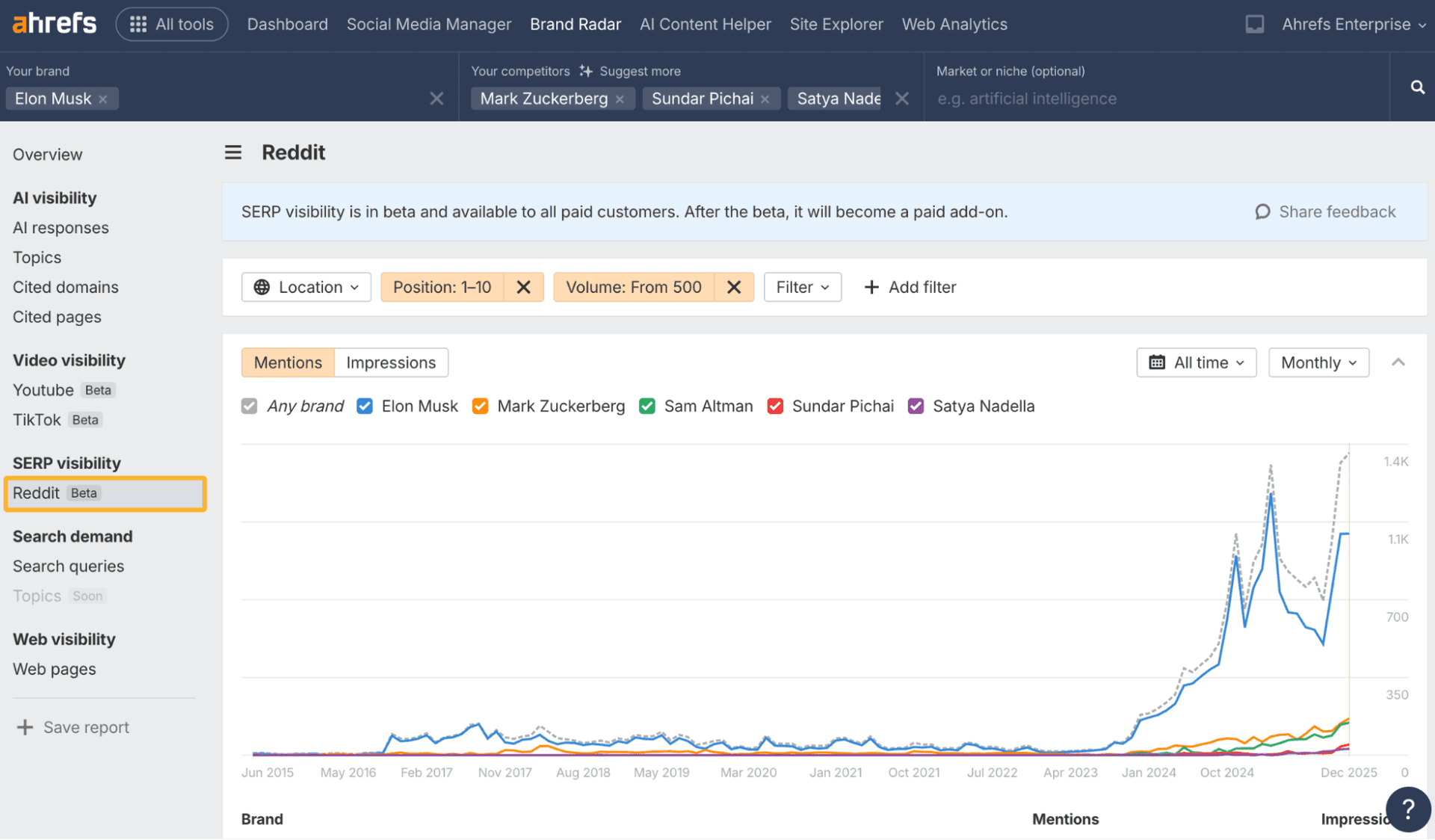
Search Engine Land’s May 13 analysis lands on a problem I keep seeing in agency work: teams rush straight to extractability and citations before the client has earned a place in the AI candidate set at all. Maryanna Franco and Rebecca Bridge frame it plainly, and they are right to do so, because the order matters. If an AI system does not already understand a brand as clear, relevant, and trustworthy, no amount of clever formatting is going to make that brand a serious recommendation.
That is the core shift agencies need to internalize. AI search visibility is not just about being easy to quote. It is about being recognizable enough to be shortlisted in the first place. Brand strategy, category definition, and entity work belong earlier in the funnel than many marketers want to admit, especially when they are under pressure to show quick wins through snippets, prompt tuning, or other surface-level AI tactics.
How to tell whether you have a recommendation problem, an extractability problem, or both
The cleanest way to diagnose the issue is to separate “can the system see us?” from “would the system choose us?” Those are not the same thing, and conflating them wastes budget fast.
Recommendation problem
A recommendation problem means the model does not yet see the brand as a meaningful option for the category. That usually shows up when the brand is ambiguous, weakly differentiated, or scattered across the web in ways that do not line up with buyer intent. In those cases, the issue is not that the answer box is badly formatted. The issue is that the brand is not legible enough to enter the shortlist.
A few signals usually point in this direction:
- The client appears only on branded searches, not on category or problem-based queries.
- Competitors are recommended repeatedly, while the client is absent.
- The brand is described inconsistently across owned pages, directories, media, and third-party references.
- The product or service proposition is generic enough that the model cannot clearly map it to a distinct use case.
If this is the problem, citation tactics are premature. The system cannot cite what it does not already consider relevant.
Extractability problem
An extractability problem is different. Here, the brand may already be in the candidate set, but the content is hard for the system to lift cleanly into an answer or citation. The model knows the brand exists and may even recommend it in some contexts, but the supporting information is buried, vague, or poorly structured.
This is where agencies should think about answer architecture, not just content volume. If the brand has the right relevance but the wrong page layout, the wrong headings, or unclear claims, AI systems may skip it for a cleaner source. In that case, the brand needs content that can be extracted without distortion.
When it is both
Most mature accounts are a mix of both problems. The brand may have decent content, but the market signal is weak. Or the brand may be well known in one niche while its web footprint is too messy for clean extraction. That is why the diagnostic has to happen before the tactic. If you treat every AI visibility problem like a formatting problem, you end up polishing pages for a recommendation set you never joined.
Why this matters more now
The business case got sharper once AI answer surfaces started reaching real scale. Google said on October 28, 2024 that AI Overviews would reach more than 1 billion global users each month and expand to more than 100 countries and territories. By May 2025, Google said AI Overviews had expanded to more than 200 countries and territories and more than 40 languages, and that they were driving over 10% more usage in the United States and India for query types that show them.
Pew Research Center’s March 2025 findings make the commercial pressure even clearer. It found that 58% of surveyed U.S. adults encountered at least one Google search with an AI-generated summary. When a summary appeared, users clicked a traditional search result in only 8% of visits, compared with 15% when no summary appeared. Source links inside the summary were clicked just 1% of the time. That is a brutal reminder that being present is not the same as being chosen, and being chosen is not the same as getting the click.
The landscape is also broader than Google. OpenAI says ChatGPT Search can answer with timely information from the web and link to relevant sources, while Perplexity says it searches the internet in real time and includes sources and citations in its answers. Once you accept that multiple answer engines are shaping discovery, the agency job becomes less about chasing one snippet format and more about building a brand that survives across systems.
What to prioritize first
If the client has a recommendation problem, start with the brand itself. Tighten the category language, sharpen the value proposition, and make sure the same entity signals appear consistently across the site, social profiles, third-party listings, and any places buyers would reasonably check. The goal is to make the brand obvious to a model that is trying to decide whether it belongs in the set at all.
If the client has an extractability problem, then move to content design. Rework pages so the model can identify the answer quickly, with clear hierarchy, direct language, and claims that map to user intent. Do not bury the point under jargon, overly clever copy, or a maze of supporting paragraphs. The easier the content is to parse, the more likely it is to be quoted accurately.
If the client has both problems, fix recommendation first. That is the part agencies most often get backward. A clean citation on a brand nobody recommends is not a win, it is a cosmetic result. The smarter sequence is simple: earn the shortlist, then make the answer easy to extract.
The agency test that saves time
Before anyone on the team starts tuning prompts or formatting answer blocks, ask these questions:
- Does the brand show up for broad category queries, or only branded ones?
- Are competitors consistently included while the client is ignored?
- Do AI systems seem to understand what the brand does, or do they misread the category?
- Is the web footprint consistent enough that the model can trust it across sources?
- If the brand does appear, is the supporting content easy to lift into a clean answer?
Those answers tell you where the real work is. And in AI search, that work usually starts earlier than people want it to, with the unglamorous stuff: category clarity, entity strength, and trust. Agencies that get that sequence right will stop polishing pages for the wrong problem and start building brands that are actually worth recommending.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?