AI visibility gaps often stem from blocked crawlers, not content quality
AI visibility can disappear even on healthy sites when crawlers are blocked, throttled, or rate-limited before they ever reach the content.

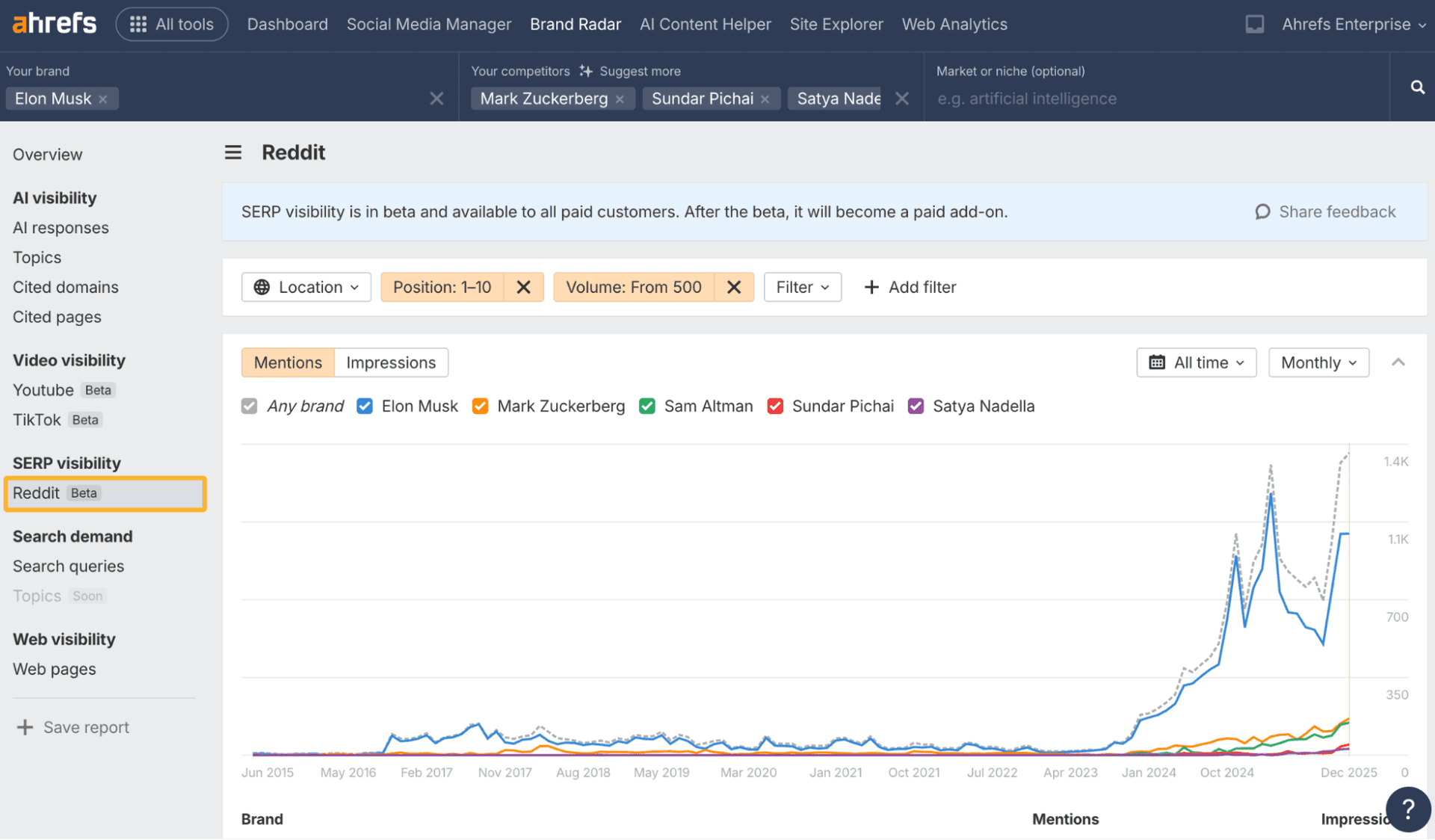
The fastest way to miss an AI visibility problem is to blame the content. On one site with normal Google Search Console data, steady traffic, and clean indexing signals, AI exposure still swung wildly from platform to platform: Google AI Mode, Copilot, Gemini, ChatGPT, and Perplexity surfaced to different degrees, while Claude and Meta AI showed zero visibility.
The real failure point is access
That pattern points to a technical break, not a content-quality failure. The content was not the issue, and the diagnostic lesson is simple: agencies need to treat AI visibility as an infrastructure problem as much as an editorial one. Search Engine Land has been pressing that same point, noting that standard SEO tools can look fine while platform-level limits quietly keep AI systems from accessing and citing content.
A Cloudflare log review in the case study made the problem more concrete. It showed tens of thousands of bot requests, with many AI bots being throttled or blocked by different mechanisms before they could properly evaluate the site. That is exactly the kind of hidden failure that can sit inside hosting settings, CDN rules, rate limits, WAF policies, security plugins, or managed WordPress controls.
Why the network layer now matters
The broader Cloudflare data explains why this keeps happening unnoticed. In June 2024, Cloudflare said AI bots accessed around 39% of the top one million internet properties using its services, yet only about 2.98% of those properties took steps to block or challenge the requests. In other words, a huge amount of AI crawling was already happening whether site owners were paying attention or not.
Cloudflare also said the higher-ranked a site is, the more likely it is to be targeted by AI bots. That matters because the clients most agencies care about, the ones already earning visibility and authority, are exactly the ones more likely to be hit by crawler traffic and access controls. The problem is not abstract: it is a live operational risk that can suppress citation share and platform-level discovery without moving classic SEO metrics very much at all.
The market has also shifted toward more granular control. In July 2025, Cloudflare announced a default block on AI crawlers for new customers unless they opted in, and it introduced pay per crawl in private beta. Cloudflare described that experiment as using HTTP 402 Payment Required, paired with price headers, so access could be tied to a pricing signal rather than a blunt allow-or-block decision. Cloudflare has also been making it easier for publishers and creators to manage robots.txt on their behalf, but that comes with an important caveat: robots.txt compliance is voluntary.
Different bots, different outcomes
One reason agencies get surprised is that not all AI crawlers behave the same way. OpenAI documents separate crawlers and user agents, including GPTBot and OAI-SearchBot, which lets webmasters think separately about model-training crawling and product-specific retrieval or browsing behavior. Anthropic similarly documents ClaudeBot and says site owners can block it with robots.txt and can use Crawl-delay to slow it down.

That separation matters because two sites with the same content can produce very different AI outcomes depending on how their infrastructure treats specific bots. A crawler used for training may be throttled aggressively while a user-facing crawler is left alone, or the reverse may happen. If a host, CDN, or plugin treats one user agent differently from another, your AI visibility may vary by platform even when the pages themselves are identical.
Cloudflare’s own network data reinforces that point. Its top request-volume AI crawlers have included Bytespider, Amazonbot, ClaudeBot, and GPTBot. When those bots are being blocked, challenged, or rate-limited differently, the result is not just fewer log entries. It is uneven discovery across AI systems, which is exactly why one client can appear in some answers and vanish from others.
What agencies should audit across every client portfolio
An AI visibility audit now needs to go beyond content, links, and schema. It should include the actual path a bot has to travel to reach the page, because that path can be interrupted long before any model evaluates the content.
- Check hosting, CDN, and WAF rules for crawler blocks, challenges, and rate limits.
- Review managed WordPress bot controls and security plugins for hidden deny rules.
- Compare robots.txt directives with live server logs, because crawler compliance is not guaranteed.
- Test key user agents separately, including GPTBot, OAI-SearchBot, and ClaudeBot.
- Look for selective policies that block AI bots on some hostnames, such as ad-supported properties, but not others.
- Inspect whether high-value pages are actually reachable by the systems clients care about most.
The key is to verify access, not assume it. A page can be indexed, ranked, and receiving normal traffic while still being invisible to a specific AI platform because the crawler is being blocked upstream. That is why log review, allowlists, deny rules, and rate-limit settings belong in the same conversation as topical authority and content strategy.
The strategic payoff for agencies
This is where agencies can separate themselves. If you can diagnose blocked crawlers early, you can prevent silent traffic loss and explain platform-by-platform visibility gaps in a way clients immediately understand. That turns you from a team that only audits content into a more technical growth partner that knows how infrastructure choices shape AI discovery.
The real warning is not that AI search is unreliable. It is that visibility can be lost at the access layer long before anyone notices a decline in rankings or a flaw in the copy. Agencies that proactively audit bot accessibility across their portfolios will catch those failures first, while the rest keep mistaking blocked crawlers for weak content.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?