SEO’s portable playbook breaks in the LLM era
The old SEO checklist fails once LLMs stop sharing the same rules. Agencies now need platform-specific tests, not recycled assumptions.

Why the old SEO checklist used to travel well
The first mistake I keep seeing is treating every AI search surface like a slightly different copy of Google. That worked in classic SEO because the major engines converged on shared standards, so one decent recommendation could usually travel. If Google liked sitemaps or structured data, Bing usually did too, and agencies built entire service lines on that portability.

That common ground was real. The Sitemap protocol gave site owners a standard way to provide details about pages to search engines, and the structured-data standard let webmasters embed machine-readable context for search engines and other applications. When the plumbing is shared, the playbook can be shared too. That is exactly the habit the LLM era breaks.
Where the LLM era breaks portability
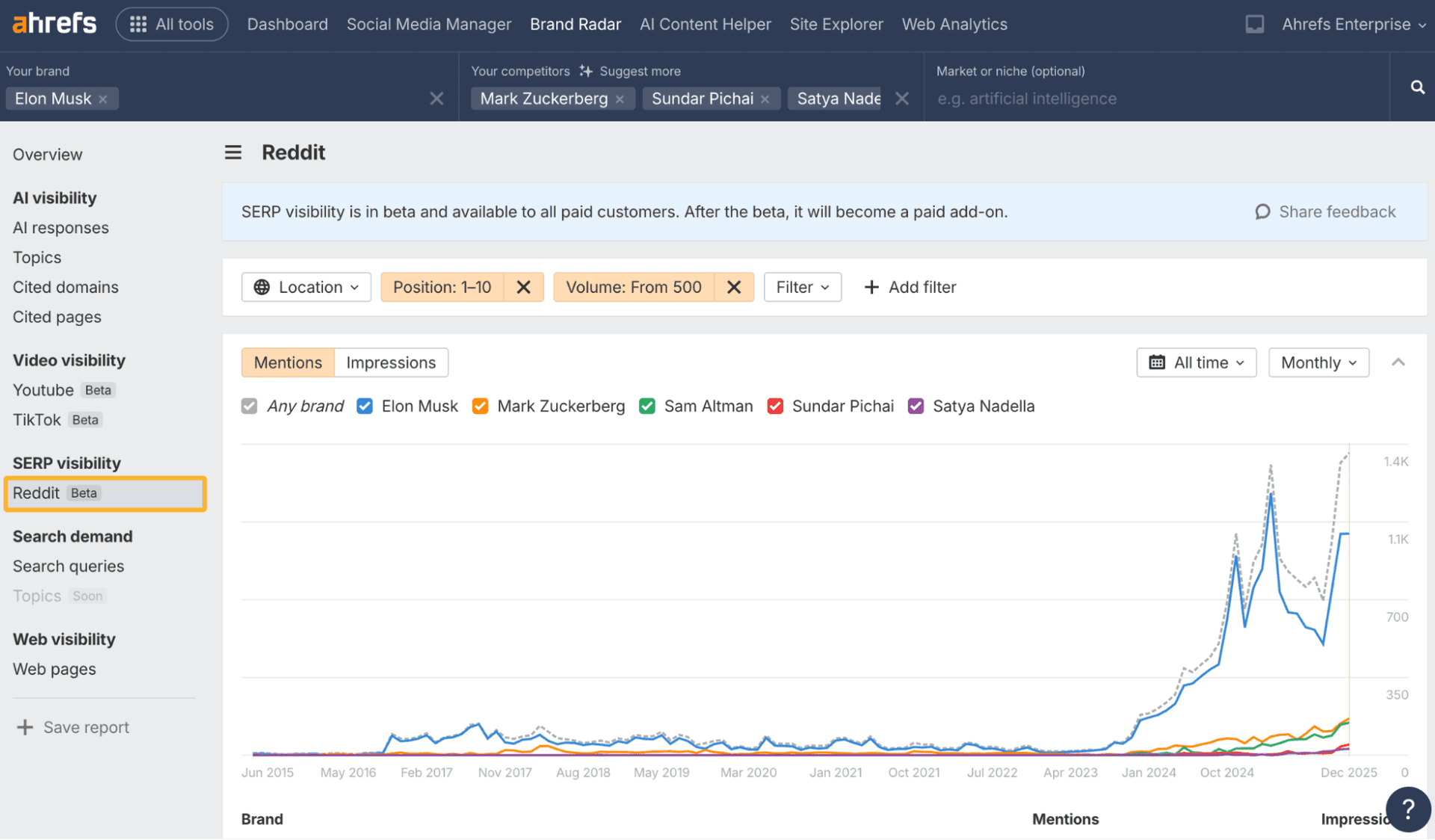
The hard truth is that ChatGPT, Claude, Perplexity, and Google’s generative features do not behave like a single search market with different logos on top. Each platform trains on different corpora, uses different crawlers, applies different policies, and produces answers through different retrieval and alignment systems. That means the same page, markup choice, or crawl setting can matter in one system and be close to irrelevant in another.
The documentation makes the split concrete. OpenAI describes separate crawlers and user agents, including OAI-SearchBot and GPTBot, and says each robots.txt setting is independent. Anthropic says it uses multiple robots for model development, web search, and user-directed retrieval. Perplexity says it uses web crawlers and user agents to gather and index information from the internet. Once you accept that those systems are not sharing one backbone, the idea of a universal optimization package starts to look lazy.
There is also a control problem underneath the technical one. Cloudflare publicly accused Perplexity of stealth crawling and said it delisted and blocked Perplexity’s crawler. That matters because it shows how quickly trust, crawl policy, and site-owner control can diverge from platform to platform. In a market this fragmented, a blanket promise that “we optimize for AI search” is usually more sales pitch than proof.
Google still matters, but only on Google’s terms
Google’s own guidance for generative AI features should not be ignored, but it should be understood correctly. Google has official advice for optimizing content for AI Overviews and AI Mode inside Google Search, and that guidance is specific to Google’s systems. AI Overviews are available in more than 200 countries and territories and more than 40 languages, and AI Mode is now appearing in Search as Google’s most powerful AI search experience.
That expansion explains why so many agencies are suddenly being asked to “do AI SEO.” The problem is that Google’s advice is not a master key for every model. It is one data point, inside one ecosystem, and it sits alongside a set of different rules from OpenAI, Anthropic, and Perplexity. In the old world, the portable playbook was a virtue. In the LLM world, portability is often the trap.
What agencies should do instead
If you sell optimization services, this is the moment to stop promising a universal checklist. Build separate testing tracks for each platform and document how each one actually behaves with your clients’ content. The real work is no longer “optimize once and distribute everywhere.” It is observe, compare, and adapt.
- separate measurement for Google’s AI features, ChatGPT-style retrieval, Claude, and Perplexity
- crawl and access checks for each bot or user agent, not a single robots.txt assumption
- platform-specific content tests to see what gets surfaced, summarized, or ignored
- evidence from your own logs and samples, not generic best-practice language
That means your service offering should look more like field testing than inherited SEO doctrine. A serious AI search engagement should include:
This is also where sales messaging needs a reset. “We use the same proven SEO framework across all AI platforms” sounds efficient, but it is exactly the wrong promise. Clients do not need another recycled checklist with AI painted on top. They need proof that you understand how each system sources information, what it rewards, and where it diverges from the others.
The visibility problem is still early and uneven
The market is not mature enough to pretend otherwise. In its Q1 2026 research, Search Engine Journal measured 177 brands across 8 AI platforms and found only 18 with any AI mentions. That is a tiny signal in a noisy market, and it explains why so many teams are still guessing. Visibility exists, but it is sparse, uneven, and highly platform-dependent.
That should change how you scope the work. If brand mentions are this rare, then the goal is not to apply a universal formula and declare victory. The goal is to build evidence, platform by platform, until you know what actually moves each system. Agencies that keep selling generic SEO assumptions will sound busy right up until a client asks why the same tactic behaves differently in every model.
The winning play now is narrower, sharper, and more honest: test each platform separately, sell to what the data shows, and stop pretending the old portable playbook survived the jump from blue links to LLMs.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?