Harvard study finds AI can outdo doctors on some diagnostic tasks
In a Boston ER test, OpenAI’s o1-preview beat two attending doctors on early triage accuracy, but the Harvard team says human oversight still matters.

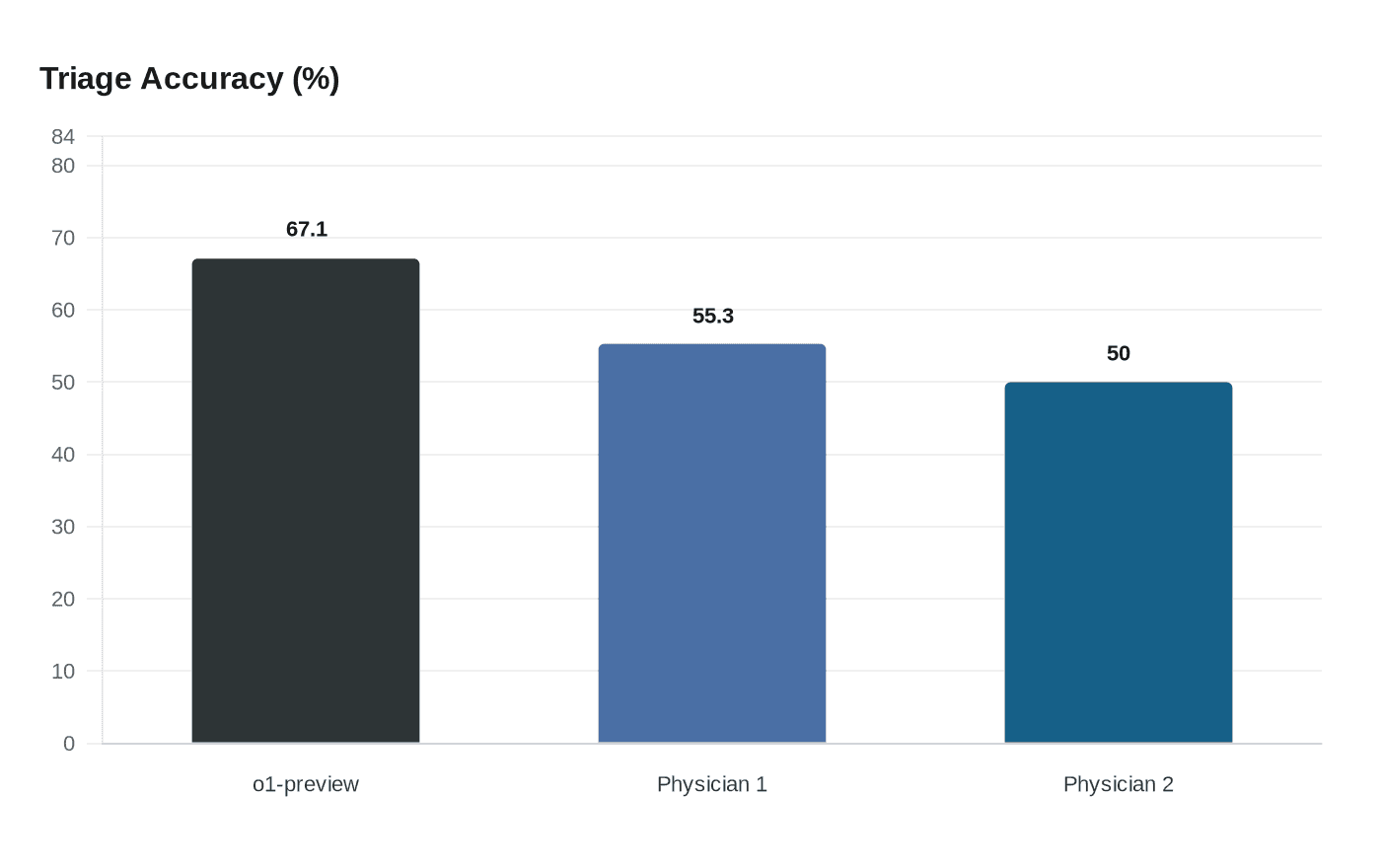
At the emergency-room door, OpenAI’s o1-preview made the right diagnostic call more often than two attending physicians when the only clues were vitals, demographics and a brief nurse note. In a Harvard-led study published in Science, the model reached 67.1% exact or very close diagnostic accuracy at initial triage on 76 cases from Beth Israel Deaconess Medical Center in Boston, versus 55.3% and 50.0% for the two experts.
That is the clearest sign yet that advanced AI may already be useful in the hardest first minutes of care, when information is sparse and decisions are urgent. The researchers found the model was especially strong in early triage and in rare, complex cases, but they also stressed that the system is not ready to stand in for human judgment in real clinical practice. The same paper tested the model at three stages of emergency care, including first physician contact and later admission decisions, underscoring that performance in a benchmark is not the same as safe deployment at the bedside.
The study, titled “Performance of a large language model on the reasoning tasks of a physician,” was led by Peter G. Brodeur, Thomas A. Buckley, Zahir Kanjee, Ethan Goh, Jonathan Chen, Arjun K. Manrai and Adam Rodman, among others. It was done with Harvard Medical School, Beth Israel Deaconess Medical Center, Stanford-affiliated researchers and others, and it framed itself against a landmark 1959 Science paper by Ledley and Lusted, a reminder that medical AI has been chasing physician-level reasoning for more than 65 years.
Beyond the emergency department, the team evaluated 143 New England Journal of Medicine clinicopathological conference cases published from 2021 through September 2024. The o1-preview model was prompted on those cases in September 2024, and attending internal medicine physicians scored the differential diagnoses with the Bond Score on a zero-to-five scale. The supplementary materials say o1-preview was released on September 12, 2024, while the newer o1 model arrived on December 5, 2024; both had a pretraining cutoff of October 2023.
The results are likely to sharpen pressure on hospitals to decide where AI belongs first: triage support, decision support and rare-disease screening, or the more sensitive work of final treatment choices. Arjun K. Manrai called the shift profound, saying, “We’re witnessing a really profound change in technology that will reshape medicine.” But Harvard Medical School researcher Arya Rao warned that clinical reasoning is not the same as moral reasoning, and Manrai said humans should remain in charge of difficult treatment decisions. Science News noted that in 2025, 1 in 5 doctors and nurses worldwide were already using AI for a second opinion on complex cases, and more than half wanted to use it that way. The near-term story is not robot doctors replacing clinicians; it is faster diagnosis, better decision support and fewer blind spots, if human oversight stays firmly in place.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?


