Google Cloud SLO guide helps monday.com focus on customer pain
Google Cloud’s SLO model gives monday.com a cleaner way to decide when reliability should slow shipping, especially as larger accounts now drive more of the business.
Google Cloud’s SLO playbook is less about dashboards than power. It gives monday.com engineering leaders a way to decide, in plain terms, when to keep shipping and when reliability has to win. That matters more now because monday.com says it serves more than 250,000 customers worldwide, and customers with more than $50,000 in ARR now make up 41% of total ARR. When the customer base gets that large and that valuable, every incident becomes a test of what the company is willing to trade away.
Why SLOs change the debate
The basic move in an SLO-driven operating model is to stop treating uptime as a vanity metric and start treating it as a proxy for customer pain. Google Cloud’s guidance frames SLOs as a way to quantify customer happiness, which is the right lens for monday.com builders who are deciding whether an alert deserves a page, a rollback, or just a note in the backlog.
That shift changes the roadmap conversation. A team no longer asks only, “Can we ship this connector, permission model, agent workflow, or data sync update by Friday?” It also asks, “What happens to the user journey if we do?” For monday.com, that is especially important because the product is increasingly positioned as an AI work platform where AI agents execute work. The more automation and orchestration the product takes on, the more a reliability miss can interrupt the actual work customers rely on.
Start with the customer journey, not the internal metric
Google’s process begins with the customer path that matters most. That means identifying critical user journeys first, then choosing the service-level indicators that reflect whether those journeys are healthy, then setting targets and measurement periods, and only then wiring up SLI, SLO, and error-budget dashboards and alerts.
For monday.com teams, that sequence is a guardrail against alert sprawl. A spike in infrastructure noise is not automatically a customer problem, and a quiet dashboard is not automatically a healthy product. The practical question is whether a customer can create a workflow, sync data, trigger an automation, load a board, or rely on an agent without hitting friction. If the answer is no, that is the incident that should rise to the top.
This is also where product managers come in. SLOs give them a language for reliability that is tied to business impact rather than just engineering detail. Instead of arguing over abstract severity levels, they can ask which workflows are degrading, how many customers are affected, and whether the issue touches the kinds of accounts that now represent a growing share of monday.com’s revenue mix.
Error budgets force a tradeoff, not a slogan
The most useful part of the model is the error budget, because it makes the tradeoff between speed and stability explicit. Google Cloud defines error budget as starting at 1 minus the SLO, then shrinking as real performance falls short. It also says burn-rate alerting can warn teams when they are in danger of violating an SLO.
For monday.com leadership, that creates a discipline that is easy to explain and hard to dodge. If a service is burning through its error budget too quickly, the team has evidence to slow down, fix root causes, and protect the platform. If it is comfortably within budget, the team has room to move faster with less risk. That is not just an engineering preference. It is a management choice about whether the next release, feature launch, or platform change is worth the reliability debt it creates.
That is especially relevant for a company that reported $972.0 million in fiscal 2024 revenue, up 33% year over year, then $1.232 billion in fiscal 2025 revenue, up 27% year over year. As the business scales, error budgets help keep growth from becoming an excuse to ignore the customer experience that makes growth possible.
What this means during incidents
SLOs also sharpen incident response. Instead of treating every alert as equally urgent, monday.com teams can prioritize the issues that are actually hurting users or about to hurt them. That is the difference between a noisy infrastructure event and a customer-facing incident.
The company’s public status page already gives a window into this mindset. It includes incident history and uptime history, and monday.com Support says users can review total uptime over the last 90 days and past incidents. The status history shows scheduled maintenance for automations and integrations on June 7, 2026, along with recent incidents in late April and late May 2026 involving connectivity issues, apps, docs, automations, and degraded performance on the EU server. That kind of public record matters because it shows reliability is not hidden inside the org chart. Customers can see it, and support teams have to explain it.
For incident commanders, the SLO frame can answer a hard question quickly: is this a page-worthy event because it is consuming budget and affecting user journeys, or is it background noise that should be tracked but not overdramatized? That distinction saves attention for the moments that actually threaten customer trust.
How engineering, product, and customer teams should talk differently
The biggest cultural change is not technical. It is conversational. SLOs give engineering, product, sales, and support a shared way to discuss reliability without each team retreating to its own vocabulary.
Engineering can say a service is within or outside budget. Product can ask whether a new workflow feature is worth the reliability cost. Customer-facing teams can explain that an issue is affecting a specific journey, not just “the platform” in the abstract. That is a more honest conversation, and it is usually a more useful one for enterprise accounts that are increasingly standardizing on monday.com for mission-critical workflows.
That matters because monday.com has already acknowledged, in its 2025 results, that customers with more than $50,000 in ARR now account for 41% of total ARR. When accounts are that material, reliability stops being a backend concern and becomes part of the commercial promise. Sales teams cannot oversell resilience, support teams cannot improvise around repeat incidents, and product managers cannot treat technical debt as invisible.
monday.com already has the raw material
There is a reason this framework fits monday.com. In a March 11, 2026 engineering post, the company said it uses Chaos Engineering to validate assumptions about service health, dependencies, and guardrails. It also said staging and production run on the same infrastructure stack. That is the kind of operational maturity that pairs naturally with SLOs, because both approaches force teams to understand failure instead of pretending it can be designed away.
The same post described controlled experiments around network jitter, pod evictions, latency spikes, and other failure modes. That is not the language of a company content to count uptime and move on. It suggests a culture that wants to learn where systems bend before customers find out where they break.
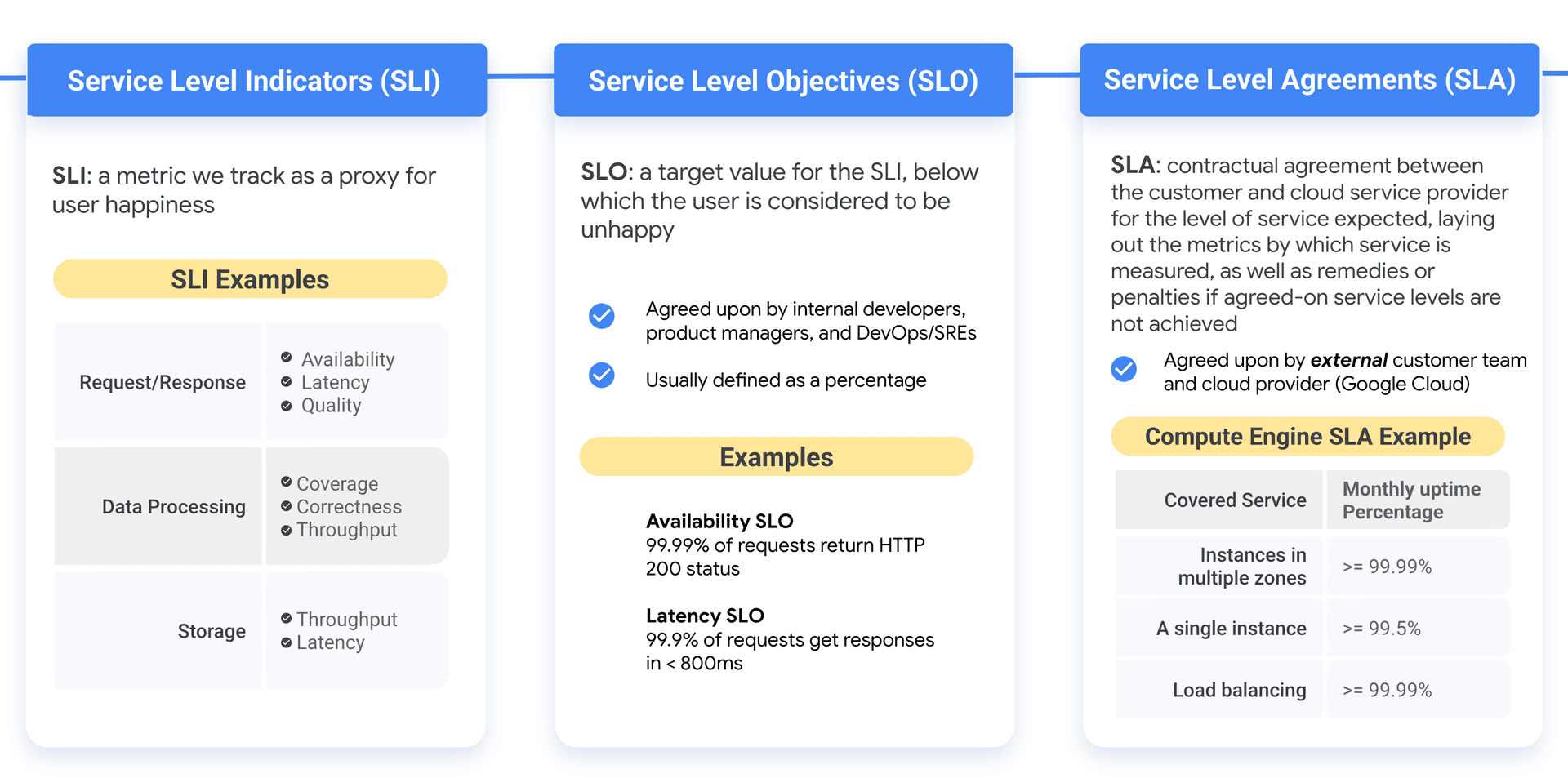
monday.com also published a 2025 blog on SLA vs. SLO vs. SLI, which is a quiet but telling signal. It shows the company is already trying to teach service teams how to set expectations and measure performance. In other words, the organization has started to build the vocabulary for the discipline Google Cloud is describing.
The operating rule monday.com builders should keep
The guiding rule is simple: if a reliability issue does not threaten customer pain, it should not crowd out work that matters more. If it does threaten customer pain, it should take precedence over new shipping velocity.
That is the real value of SLOs and error budgets for monday.com. They give leaders a clean way to choose, explicitly, between moving faster and protecting the product promise. In a platform that now carries more automation, more AI behavior, and more mission-critical workflows for bigger customers, that is not a nice-to-have. It is the operating system for scaling without losing trust.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?