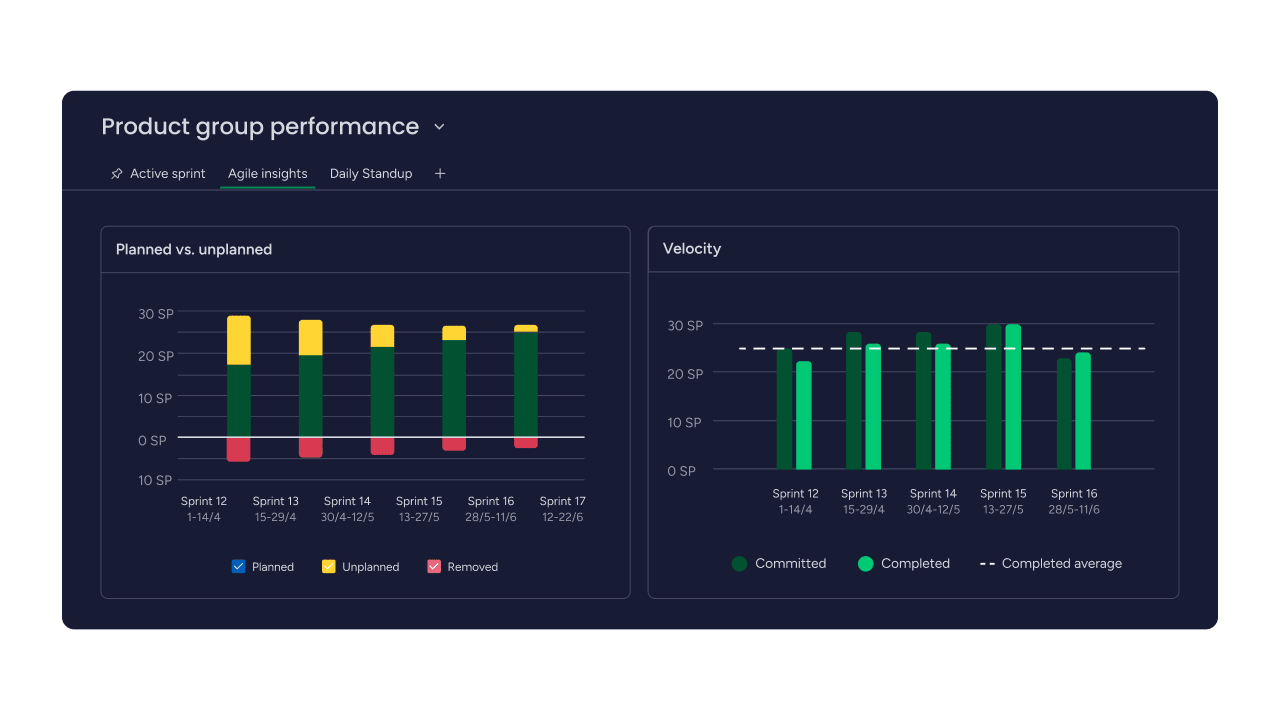
Monday.com urges blameless postmortems to prevent repeat incidents
Monday.com’s real warning is simple: a postmortem only works when it turns lessons into owned tasks. Without structure, blame-free review, and follow-through, repeat incidents are almost guaranteed.
Most postmortems feel useful while everyone is still in the room. The failure comes later, when the notes are vague, the action items are nobody’s job, and the same incident shows up again in a new form. Monday.com’s guidance pushes hard against that pattern: make the review blameless, make it structured, and make sure the fixes live inside an ongoing workflow, not a forgotten document.
Why the review has to wait until the pressure eases
The most useful postmortems do not start in the heat of the incident. They start after the immediate pressure has eased, when teams can still reconstruct what happened without being swept up in adrenaline or defensive storytelling. That timing matters in a fast-moving SaaS environment, where engineering, product, and customer-facing teams all need a clear account of what happened before memory gets distorted by urgency.
Monday.com’s template approach is built around that reality. Instead of letting every team invent its own format, it calls for a consistent structure that captures the timeline, the impact, and the root cause. That turns a postmortem from a loose conversation into a document people can use later, compare across incidents, and actually act on.
Blameless is not soft. It is operational discipline
The word blameless can sound polite until you look at what it does in practice. The goal is not to soften accountability; it is to surface process gaps and system design failures that a blame-driven review usually buries. When people know the meeting is about learning rather than punishment, they are far more likely to tell the truth about what they saw, what they missed, and where the system failed them.
That logic lines up with broader incident-management practice. Google SRE treats incidents and outages as inevitable at scale, which is why postmortems are an essential tool rather than an optional ritual. Google’s definition is strict and useful: the postmortem is a written record of the incident, its impact, the mitigation steps taken, the root cause or causes, and the follow-up actions meant to keep it from happening again.
Atlassian’s guidance goes in the same direction. Its blameless model assumes employees acted with the best intentions based on the information they had at the time. The point is to understand what happened, why it happened, how the team responded, and what needs to change before the same failure repeats.
The real value is in the next incident that never happens
A postmortem that ends with a vague lesson is mostly theatre. A postmortem that assigns owners, deadlines, and measurable action items becomes part of the operating system. Monday.com’s own guidance is explicit about that, saying the work should not stop at reflection. The fixes need to be tracked, and the outcomes need to be measured.
That is the difference between a retrospective and a control system. Teams can track incident frequency, recovery time, and completion rates for action items to see whether the process is actually reducing risk. In a company like monday.com, that kind of measurement is not an academic exercise. It tells managers whether the organization is improving or just recycling the same lessons in new meetings.
For engineers and product managers, this is where the template matters most. If a platform issue, workflow bug, or release failure is captured only in a slide deck or a loose doc, the action item can vanish into the next planning cycle. If it is captured inside an ongoing workflow system, the issue stays visible until someone closes the loop.
Why this matters even more in a SaaS company
monday.com is not just talking about abstract best practices. It runs a customer-facing platform serving more than 250,000 customers worldwide, which means reliability is part of the product promise. When a workflow platform stumbles, the damage is not limited to uptime. It can break customer trust, stall internal work, and make the company look less dependable exactly when users need it most.
That is why the company’s status page matters as part of the story. monday.com says it uses that page for real-time and historical system health, and that it will communicate interruptions there. The page tracks uptime for components including Platform, Automations, Integrations, API, and monday workdocs, and it showed 60-day uptime figures of 100% for most components, 99.95% for Automations, and 99.98% for monday workdocs. That level of visibility fits the logic of a mature incident process: if the company expects customers to trust the platform, it has to show that it treats operational transparency seriously.
The infrastructure details reinforce the point. monday.com says it hosts across multiple Amazon Web Services Availability Zones in the United States, the European Union, and Australia, and that it maintains a disaster recovery site in another AWS region. It also says its security model follows standards and best practices including ISO 27001, ISO 27018, and the OWASP Top 10. In a distributed SaaS business, postmortems are not just about fixing one outage. They are part of a broader system for keeping services resilient across regions and reducing the odds of the same failure rippling outward.
What workers at monday.com should take from the template
For teams using monday work management or monday dev, the message is straightforward: the postmortem belongs in the same discipline as the rest of the work. A review that ends in a shrug is a waste of time. A review that creates visible tasks, clear owners, and deadlines gives the organization a way to learn in public and improve in place.
That is especially important in a high-growth environment where product launches, customer expectations, and internal execution all move quickly. Monday.com’s template and related materials, including incident management and root-cause-analysis templates, are trying to standardize that learning process so it does not depend on who is in the room or how forceful the manager happens to be. The point is not just to write down what went wrong. It is to make sure the same failure has a harder time happening again.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?