Practical AEO toolkit uses AI assistants for research, monitoring, workflow
The smartest AEO stacks are small: use AI assistants to find opportunities, track citations, and prove visibility before clients ask for vanity reports.
AI assistants belong in the research stack, not just the drafting stack
If you are trying to grow AI search presence for clients, the biggest mistake is treating ChatGPT, Claude, and Perplexity like interchangeable copy machines. Used well, they are research environments. They show how entities are represented, which sources get pulled into answers, and where competitors keep winning visibility before you ever publish a page.
That is why the most practical AEO toolkit is not a giant martech shopping list. It is a short, disciplined stack built around the work agencies actually have to do: discover answer opportunities, monitor citations, test visibility, and report outcomes in a way that client teams can understand. The point is not to chase every new tool. The point is to build a repeatable workflow that protects margins.
Start with the assistants that surface the work
ChatGPT search, which OpenAI announced on October 31, 2024, was designed to provide fast, timely answers with links to relevant web sources. OpenAI rolled it out to all logged-in users in supported regions on December 16, 2024, then expanded it to everyone in supported regions on February 5, 2025. That matters for AEO because ChatGPT is useful when you want to see how a broad, general-purpose assistant frames a query and what it considers worth citing.
Claude is a different kind of instrument. Anthropic launched Citations for its API on June 23, 2025, letting Claude cite specific passages from source documents and provide verifiable responses with built-in source tracking. That makes it a strong fit for source-heavy work, especially when you are validating claims, checking whether a source passage actually supports an answer, or drafting content that needs cleaner evidentiary support.
Perplexity is the most explicitly search-oriented of the three. It describes itself as an answer engine that searches the web in real time and returns answers backed by citations. For agencies, that makes it a clean place to test what a client might surface in a live answer environment, especially when you want citations to show up alongside the synthesis instead of buried after the fact.
Use them for research, not just output
The real value comes when you turn those assistants into a routine. Query them with the same prompts prospects would use, then compare the answers across platforms. That tells you more than a rank tracker ever will, because AEO is about how systems represent entities, which competitors appear, and which sources are trusted enough to be pulled into the answer.
That workflow is especially useful for:
- Competitive research, where you want to see which brands keep appearing in AI answers for a topic cluster.
- Content gap analysis, where the absence of a source, definition, or comparison is often the opportunity.
- Prompt testing, where slight wording changes reveal very different answer structures.
- Topical coverage audits, where you check whether the assistant treats your client as an authority or skips them entirely.
- Structured drafting, where the assistant helps organize a page around the questions AI systems actually answer.
The important habit is consistency. You are not looking for one perfect prompt. You are building a repeatable query set that lets you see how answers change by platform and over time.
Match the tool to the job
ChatGPT is the broadest of the bunch, which is exactly why it is useful for synthesis and early-stage exploration. Claude is the one you reach for when source fidelity matters and you need a clearer trail back to passage-level evidence. Perplexity is the most direct for citation-led answer surfacing and real-time web search.
That split matters in agency work because not every client problem is the same. If you are mapping a category, ChatGPT can help you see the shape of the conversation. If you are checking whether a claim is truly supported, Claude’s citation workflow gives you a tighter read. If you are testing live answer visibility, Perplexity is often the quickest way to see what the web-backed answer layer is doing right now.
This is also why the article’s practical frame of four tools used regularly, plus three more under evaluation before they join the team stack, makes sense. Agencies do not need a bloated suite. They need a small set of tools they can actually train on, document, and use across accounts without destroying efficiency.
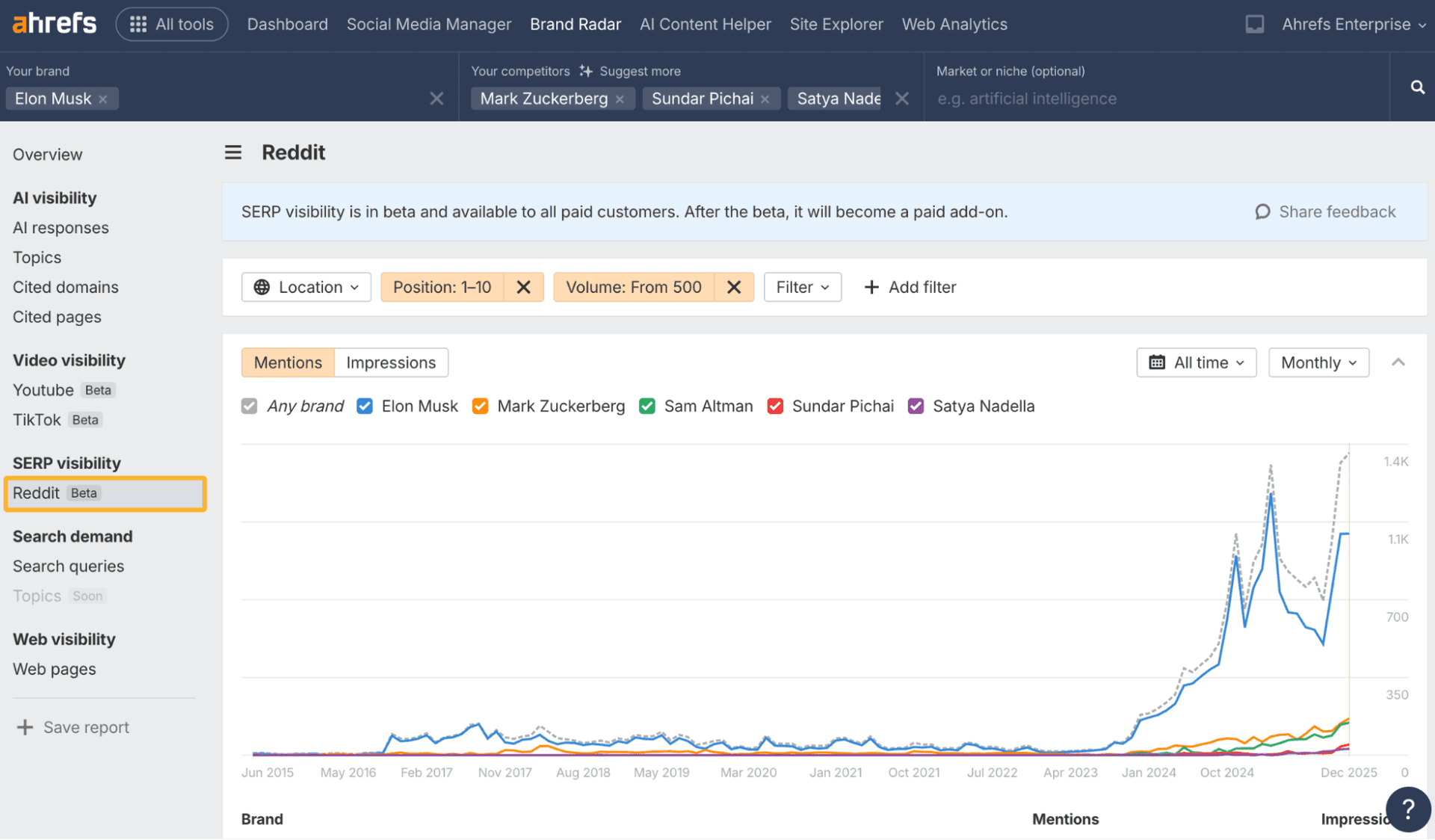
Monitor the answer layer clients are already entering
Google’s AI Overviews are now part of that visibility fight. Google launched AI Overviews in the United States on May 14, 2024, after earlier testing as Search Generative Experience in 2023. Google says the feature is integrated with core web ranking systems and includes links so users can explore further.
For agencies, that means AI visibility is no longer a side experiment. It is woven into the core search experience, and it can affect whether a brand shows up in the first answer block or disappears beneath it. Ahrefs has pointed out that the feature started as Search Generative Experience in 2023 before its U.S. launch, which is a useful reminder that this layer has already moved from trial to fixture.
The operational move is simple: use your assistants to test the query, then check whether the client appears in AI Overviews, whether the sources cited are competitors, and whether the content format is doing enough to earn inclusion. That is where AEO becomes measurable.
Tie visibility to the buying process, not vanity metrics
The reason this work has real business value is that buyers are doing more of the evaluation before sales ever gets a conversation. 6sense’s 2025 B2B Buyer Experience Report says typical B2B purchases involve 10 or more people and take close to a year. It also says buyers shortlist about 4 of 5 vendors by day one and buy from that shortlist 85% to 95% of the time.
That changes the reporting conversation. If your client is not present in AI answers during early research, they may never make the shortlist that matters. 6sense also says the point of first contact shifted from about 69% of the journey in 2024 to 61% in 2025, roughly 6 to 7 weeks sooner. That means the window for influence is opening earlier, and AI-answer visibility is part of that window.
So the right report is not just “we gained mentions.” It is: here are the prompts we tested, here are the assistants that cited us, here are the competitors that kept appearing, and here are the topics where a client page is still missing from the answer set.
Build a stack you can service profitably
The best AEO stack is the one your team can use every week without turning the workflow into a science project. Start with the assistants that help you research and test answers. Add the monitoring layer that tells you when AI systems are citing your client and when they are not. Keep the workflow lean enough that you can reuse it across accounts, because that is what protects margin.
AEO is already a practical discipline. The agencies that will win are the ones that stop treating AI systems as black boxes and start using them as structured research surfaces, one query, one citation, and one client report at a time.
This article was produced by Prism’s automated news system from verified source data, official records, and press releases, then run through automated quality and moderation checks before publishing. The system is built and supervised by the people who set the standards it runs under. Read our full AI policy.
Did this article answer your question?