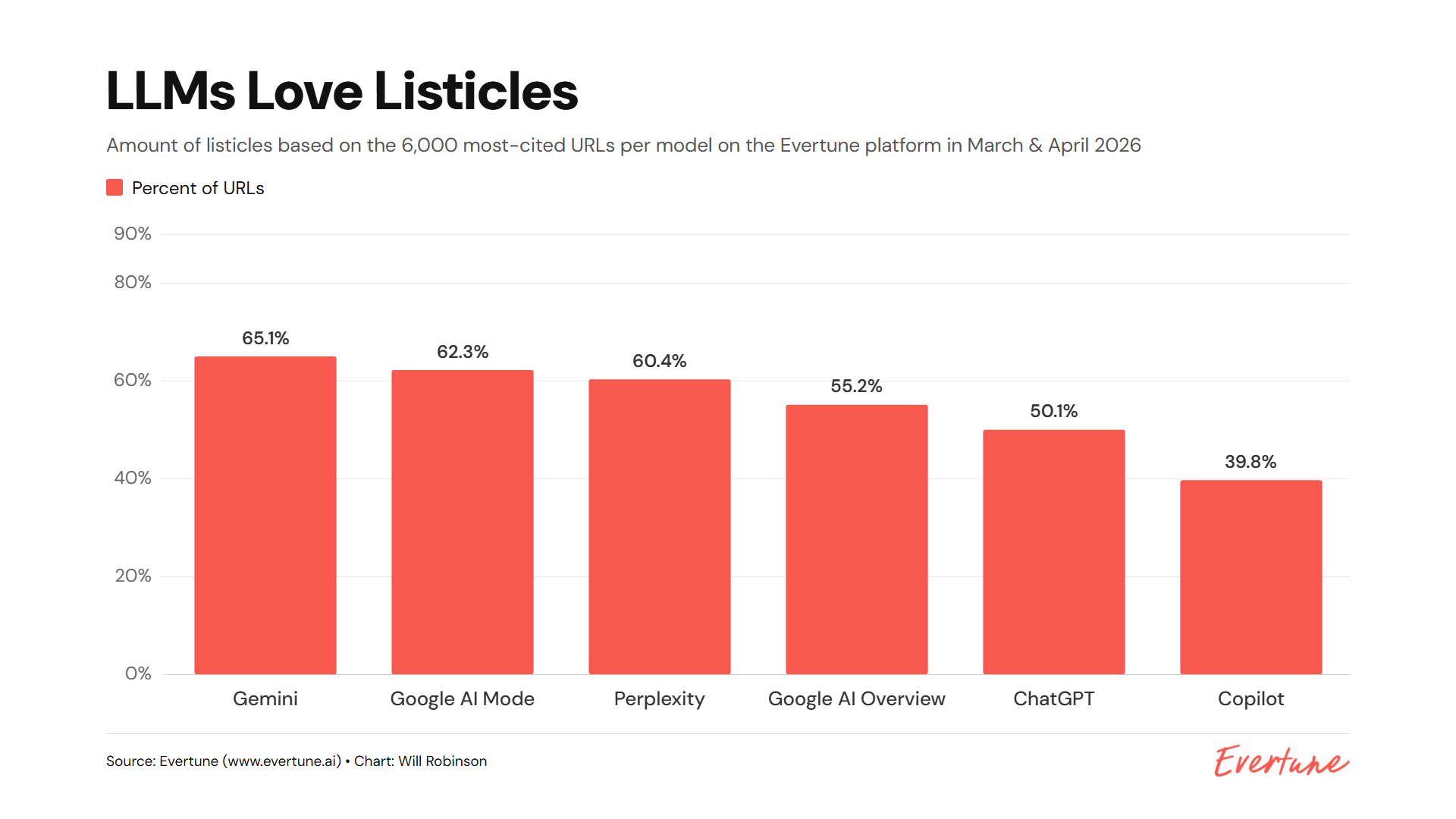
AI crawler optimization turns technical SEO into site visibility playbook
AI visibility now depends on whether machines can fetch, render, and trust your pages, not just rank them.

The crawl budget story just got bigger
AI search visibility starts with boring plumbing, and that is exactly why so many sites miss it. If a crawler cannot fetch the page, render the content, or trust the canonical version, the page may never make it into an AI answer, a recommendation, or a cited result. The technical foundation is still classic SEO, but the payoff is wider now because the same page can feed rankings, generative answers, and downstream agentic workflows.
Google’s own documentation makes the stack feel less mystical than the hype suggests. Search processes JavaScript in three phases, crawling, rendering, and indexing, and that means a page can look fine to a human while still failing at one of the machine steps. OpenAI’s search products also rely on crawlers and user agents, including OAI-SearchBot, which means site owners now have to think about bot access as part of visibility, not as an afterthought.
Crawlability is the first gate
If the crawler cannot reach the URL, everything else is academic. Google says Googlebot reads robots.txt and skips blocked URLs, so access control is not just a polite suggestion, it is a hard stop for discovery. The same is true for links: Google treats links as a signal for relevancy and for finding new pages to crawl, so a site architecture that buries important pages behind weak internal linking is still shooting itself in the foot.
This is where a lot of modern sites trip over their own polish. Heavy JavaScript interfaces, infinite-scroll patterns, and slick navigation can look great in a browser while leaving crawlers with thin or incomplete access paths. If a page is easy for a human to tap through but difficult for a bot to traverse, the page is not really visible in the way that matters for AI systems.
Rendering has to work for machines, not just browsers
Google’s JavaScript guidance is blunt about the risk: blocked JavaScript resources can prevent proper rendering. That means if CSS, scripts, or key assets are hidden from Googlebot, the crawler may not see the page the way your users do, or may not see the page fully at all. In AI search, that is not just an SEO nuisance, because incomplete rendering can also reduce the odds that a system can interpret the page cleanly enough to cite it.
That is why server-side rendering keeps showing up in serious technical conversations. web.dev says SSR is often chosen because it delivers a more complete HTML experience that crawlers can interpret, and that is still one of the cleanest ways to reduce machine friction. You do not need every page to be SSR-only, but you do need to know which pages matter most and whether the important content arrives in the initial HTML or only after a pile of client-side work.
Structured data is interpretation fuel
Crawlability gets the page into the system; structured data helps the system understand what it is looking at. Google says structured data should be implemented in supported formats such as JSON-LD, Microdata, or RDFa, and it uses that markup to understand content. That is especially important when you want machines to distinguish a product, a how-to, a recipe, an event, or a FAQ page without guessing.
The part that is easy to miss is access discipline. Google’s structured data guidelines say not to block structured data pages from Googlebot using robots.txt, noindex, or other access control methods. If the markup lives on pages that crawlers cannot access, you have not really added structured data in a meaningful way for search or AI retrieval.
Canonicalization still decides which version counts
Duplicate pages are not just a housekeeping problem anymore. Google defines canonicalization as the process of selecting the representative canonical URL for a piece of content, and that choice affects which version gets treated as authoritative. Google also notes that it may select a different canonical than the one a site owner prefers, which is exactly why inconsistent URL structures can quietly dilute trust and authority signals.
For AI visibility, canonicals matter because systems need a clean version to cite, summarize, and associate with topical authority. If the same article exists under multiple URLs, or if trailing slashes, parameters, and pagination create messy duplicates, the machine may resolve the wrong page or split signals across too many versions. The fix is not glamorous, but it is simple: keep URL patterns consistent, use canonicals deliberately, and make sure the representative page is the one you actually want surfaced.
Robots.txt is now a policy conversation, not just a crawler hint
OpenAI says its products use crawlers and user agents, including GPTBot and OAI-SearchBot, and it notes that webmasters may need to update robots.txt if they want OAI-SearchBot to access their pages. That turns crawler access into an operational decision rather than a background SEO setting. If your site wants to be visible in AI search experiences, you need to know which bots you are allowing, which ones you are blocking, and whether that aligns with your business goals.
Cloudflare adds another layer to the reality check. It says AI crawlers may scrape webpages thousands of times for every referral they send, and it also points out that robots.txt compliance is voluntary and does not technically prevent crawling. That is the uncomfortable truth for publishers: robots.txt can express intent, but it is not a force field, so access strategy has to be paired with monitoring and, where necessary, stronger controls.
The practical playbook is still a technical audit
The fastest way to improve AI crawl visibility is to audit the site the way a machine experiences it. Start with the pages that matter most commercially, then check whether they are reachable through crawlable links, whether their canonical URLs are stable, whether their primary content appears in rendered HTML, and whether their structured data is accessible. If a page depends on blocked scripts, blocked pages, or fragile client-side rendering, you are asking too much of the crawler.
- Make sure important pages are linked from crawlable paths, not trapped behind scripts alone.
- Confirm that the preferred canonical URL is the one you actually want indexed and cited.
- Use supported structured data formats and keep those pages open to crawlers.
- Review robots.txt with the specific bots you care about in mind, including OAI-SearchBot.
- Test whether the main content appears cleanly in rendered HTML, not only after JavaScript runs.
A useful internal checklist looks like this:
Why this matters more now
Google said in May 2024 that AI Overviews are sending people to a greater diversity of websites when they need help with more complex questions, and that links inside AI Overviews can get more clicks than a traditional web listing for the same query. That is a big deal for anyone treating AI search as a side channel. The pages that are easiest for machines to fetch, render, and interpret are the ones most likely to be pulled into those answers and, in turn, get the traffic and authority that come with them.
The real shift here is not that technical SEO has been replaced. It is that the stakes have expanded. A site that is cleanly crawlable, properly rendered, canonically consistent, and structured for machine interpretation is no longer just better optimized for Google search. It is better prepared for the next layer of discovery, where AI systems have to understand the page well enough to trust it.
Know something we missed? Have a correction or additional information?
Submit a Tip