Higher reasoning in GPT-5.2 changes citations, discovery paths in AI search
Turn up reasoning, and GPT-5.2 changes which brands get cited. The winners are the pages that help the model think, not just the pages with the loudest logo.
The citation graph moves when the model thinks harder
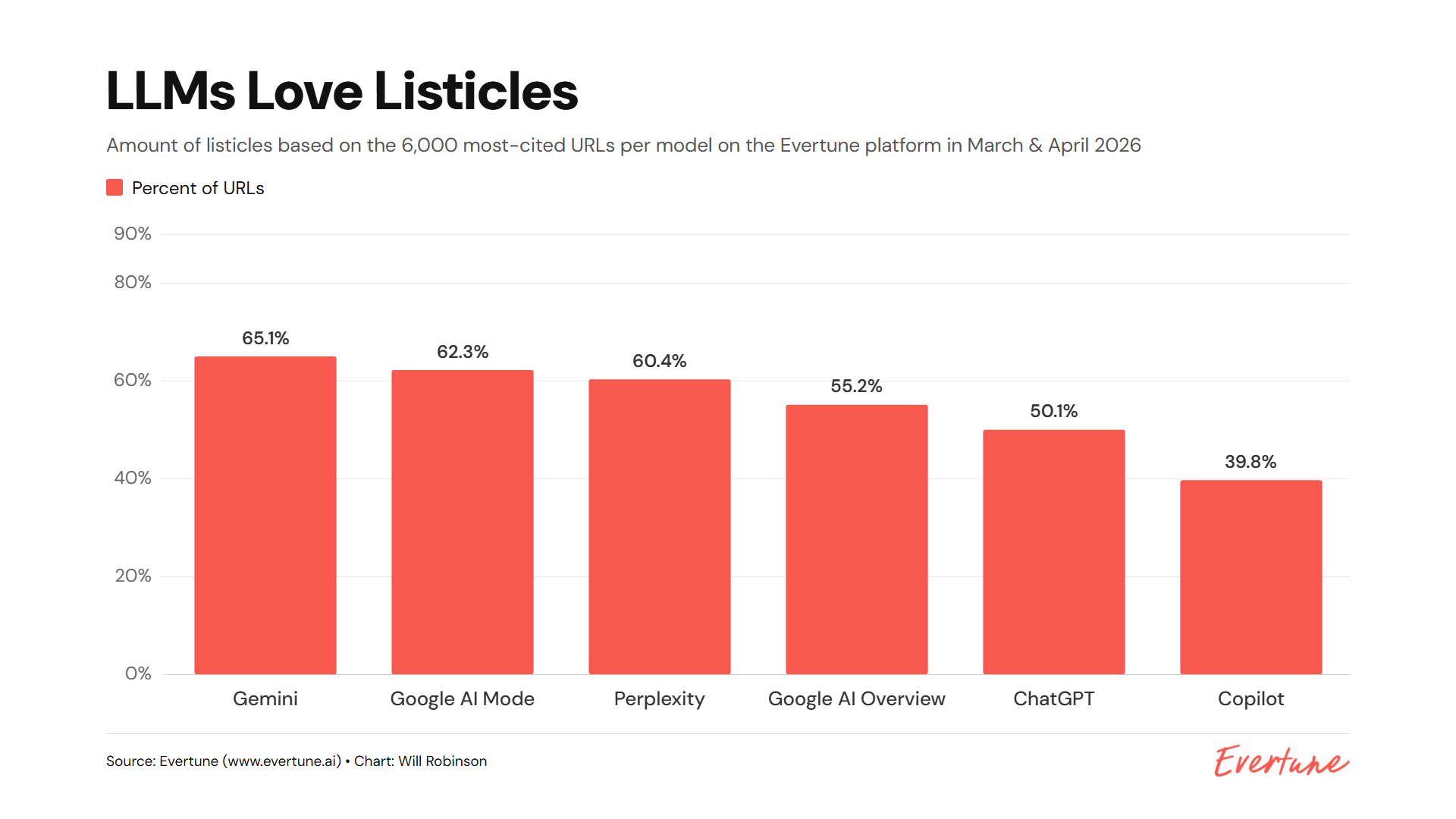
Deeper reasoning does not just improve the answer, it rewires the path to the answer. In a 200-response test of GPT-5.2, citations rose from 50% to 68% when reasoning was set higher, average sources per cited response climbed from 2.6 to 4.5, and fan-out queries jumped 4.6x. Fan-out queries are the internal sub-questions the model fires off before it responds, which means the model is effectively doing a broader research pass before it decides what to cite.

What the test actually covered
The analysis ran 100 prompts twice, once with minimal reasoning and once with high reasoning, for 200 total responses. Those prompts spanned 20 buyer journeys across four verticals: B2B SaaS, Finance, Consumer Tech, and Health/Lifestyle. Each journey moved through five stages, Problem, Exploration, Comparison, Validation, and Selection, which makes this more useful than a generic benchmark because it tracks how AI search behaves across the full buying path.
That structure matters. A model that is only given a single product query can appear stable, but a model that is pushed through the full journey has to expand its search, reconcile more evidence, and decide which domains deserve to stay in the answer. The Search Engine Land analysis by Kevin Indig, Carlos Silva, Alex Lindley, and Oshen Davidson uses Semrush AI Visibility Toolkit data to show that reasoning depth changes both the citation set and the discovery path, not just the final wording.
The brands that win are not always the usual suspects
The clearest sign that this is not a static ranking problem is the domain spread. High reasoning pulled from 173 unique domains, while minimal reasoning pulled from 127. Even more telling, 99 domains appeared only under high reasoning and never showed up in the minimal-reasoning runs, and domain overlap between the two modes was only 25.6%.
That kind of turnover tells you something blunt: authority alone does not lock in visibility. A brand can be strong enough to show up in one answer mode and invisible in another if the model decides it needs a wider, deeper, or differently framed set of sources. That lines up with earlier Semrush research showing that Wikipedia and Reddit often outrank official marketing pages in AI citations, which is exactly the kind of result that frustrates brands expecting their own domain to carry the day.
Early-funnel content matters more than most teams think
One of the most useful findings in this analysis is that early-funnel visibility does not vanish once the model gets closer to a purchase decision. Top-of-funnel content cited during the Problem stage is more likely to persist through later stages like Comparison and Selection when high reasoning is turned on. That is a big deal for publishers because it means the pages that explain the problem, define the category, and frame the decision can keep paying off after the model moves into evaluation mode.
- Problem-led explainers that name the pain point clearly
- Comparison pages that use clean, structured distinctions
- Validation content with proof, examples, and benchmarks
- Selection pages that make the final choice easy to justify
This is where practical content strategy gets more interesting than the usual “publish more bottom-funnel pages” advice. If the model is reasoning harder, then the content that helps it map the territory can travel farther than the page that only closes the sale. In practice, that means building coverage around:
Authority still matters, but topical depth and structure decide whether that authority can be reused as the model keeps exploring.
Reasoning-heavy search rewards breadth, not just brand strength
The bigger strategic takeaway is that AI search visibility behaves more like a research workflow than a fixed leaderboard. When GPT-5.2 reasons more deeply, it reaches farther, cites more sources, and changes the domain mix enough that one visibility score can hide real differences. That is why measurement teams should stop averaging together behavior that is actually different and start splitting prompt tracking by reasoning mode.
The broader industry data points in the same direction. AirOps reported in a 2025 study with more than 45,000 citations that visibility fluctuates sharply, with roughly 57% of disappeared brands resurfacing later and only about 30% staying visible in back-to-back responses. A later AirOps report sharpened that picture further, saying only 30% of brands stay visible from one answer to the next, 20% across five consecutive runs, and that brands earning both a citation and a mention were 40% more likely to reappear than brands that earned citations alone.
That is the part publishers should care about most. A single citation is not the same thing as durable discoverability. If a brand appears only when the model takes a shallow path, it is vulnerable the moment the system asks more questions.
Why GPT-5.2 changes the game
OpenAI introduced GPT-5.2 on December 11, 2025 and positioned it as its most capable model series yet for professional knowledge work and long-running agents. OpenAI also rolled out GPT-5.2 Instant, Thinking, and Pro in ChatGPT and the API, which makes reasoning depth a live variable, not a theoretical one. That matters because models built for multi-step work do not just summarize what they find, they actively search, compare, and filter before they cite.
For publishers, the practical lesson is straightforward. Authority gets you into the conversation, structure helps the model traverse your content, and topical depth helps you survive when the system thinks harder. The brands that will keep showing up are the ones that can be rediscovered from multiple angles, across multiple stages, and under multiple reasoning settings.
Know something we missed? Have a correction or additional information?
Submit a Tip